Spark快速大数据分析——Spark的部署与使用(柒)
![[lab.magiconch.com][福音戰士標題生成器]-1727613037515](https://s2.loli.net/2024/09/29/I861KJRCQPwropA.jpg)

软件环境
强烈提示:
请按照对应配套版本来进行环境配置!
- Hadoop-3.2
- IDEA 2021.3.2
- Spark-3.1.3 搭配 scala版本:2.12 构建方式:IDEA导入本地JAR,Spark库
- JDK 8
- Hive 3.1.3
- MYSQL 8.0.2
- WSL 2 Ubuntu20.04
备注:在安装Spark-3.1.3 之前,请首先安装Hadoop3.2。
Spark在WSL2中的部署
windos下的压缩包和Linux下安装的压缩包完全一致,我们将压缩包送入root用户的目录下:

打开命令行,切换到hadoop用户:
su hadoop
切换以后再使用解压命令:
hadoop@LAPTOP-74GAR8S9:/usr/local$ sudo tar -zvxf /home/jszszzy/spark/spark-3.1.3-bin-hadoop3.2.tgz -C /usr/local/
切换目录到解压目录下:
hadoop@LAPTOP-74GAR8S9:/usr/local$ cd /usr/local
修改对应目录的名字:
hadoop@LAPTOP-74GAR8S9:/usr/local$ sudo mv ./spark-3.1.3-bin-hadoop3.2/ ./spark
增加用户组权限:
hadoop@LAPTOP-74GAR8S9:/usr/local$ sudo chown -R hadoop:hadoop ./spark
进入目录修改配置文件:
hadoop@LAPTOP-74GAR8S9:/usr/local$ cd spark/
hadoop@LAPTOP-74GAR8S9:/usr/local/spark$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
使用vim修改配置文件,添加以下内容:
hadoop@LAPTOP-74GAR8S9:/usr/local/spark$ vim ./conf/spark-env.sh
添加hadoop支持:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
在测试前请先打开ssh和hadoop还有hive:
打开ssh:
hadoop@LAPTOP-74GAR8S9:/usr/local/hadoop$ sudo service ssh restart
[sudo] password for hadoop:
* Restarting OpenBSD Secure Shell server sshd [ OK ]
打开hadoop:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ cd /usr/local/hadoop
hadoop@LAPTOP-74GAR8S9:/usr/local/hadoop$ ./sbin/start-dfs.sh
Starting namenodes on [localhost]
如果有需要还需要打开Mysql和hive,具体可参考hive安装篇。
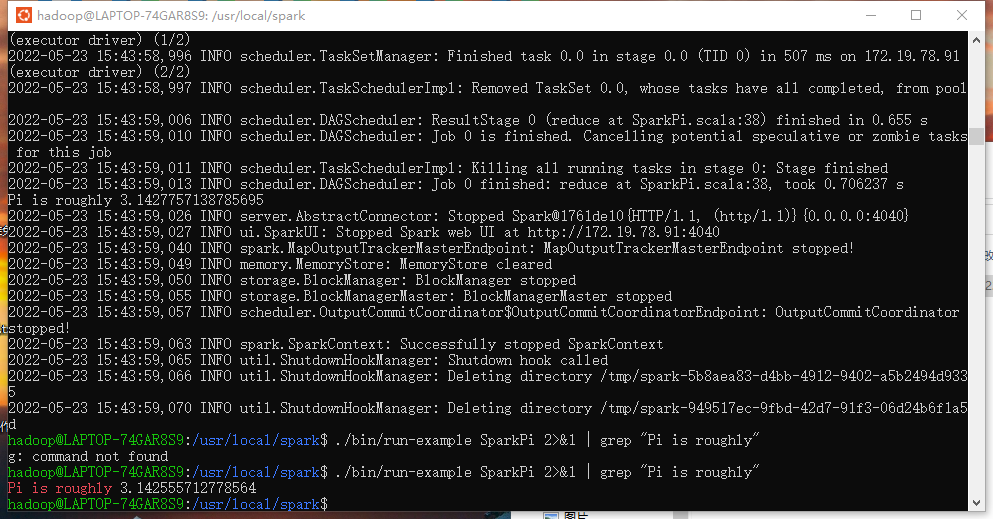
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
得到pi=31.4即可。
使用IDEA连接WSL2运行Spark代码
打开IDEA创建一个sbt项目,如果你不会创建,请参考专栏对应文章。
找到编辑编译配置项目,具体如下图:

打开以后找到如下选项:
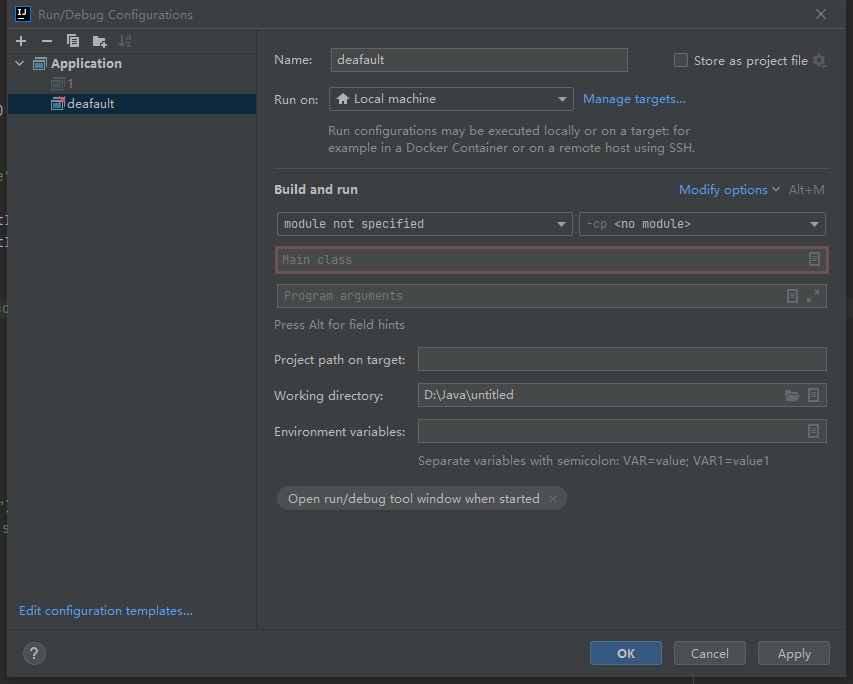
打开Run on选项选择新建运行环境,并选择WSL,选择会会让你配置wsl的运行环境:
他自动检测到了WSL的JDK,实际上安装了两个JDK,应该使用Spark所要的jdk。
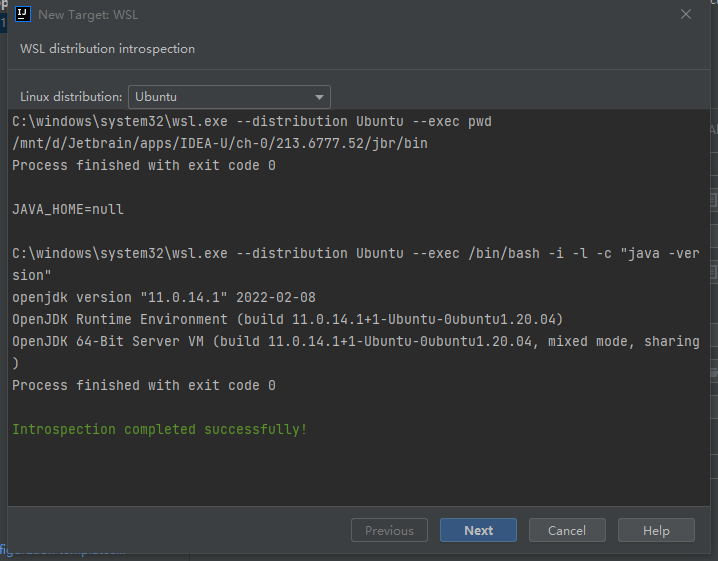
我们点击next,手动配置一下。
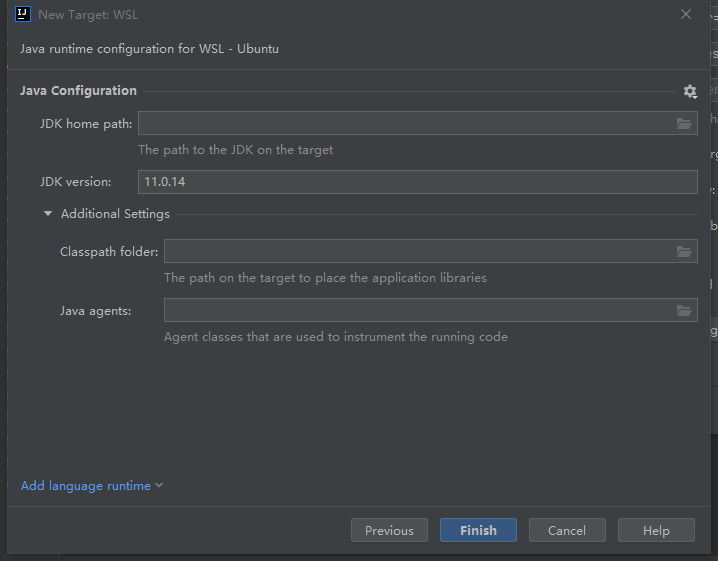
具体怎么填写,可以参考我的。
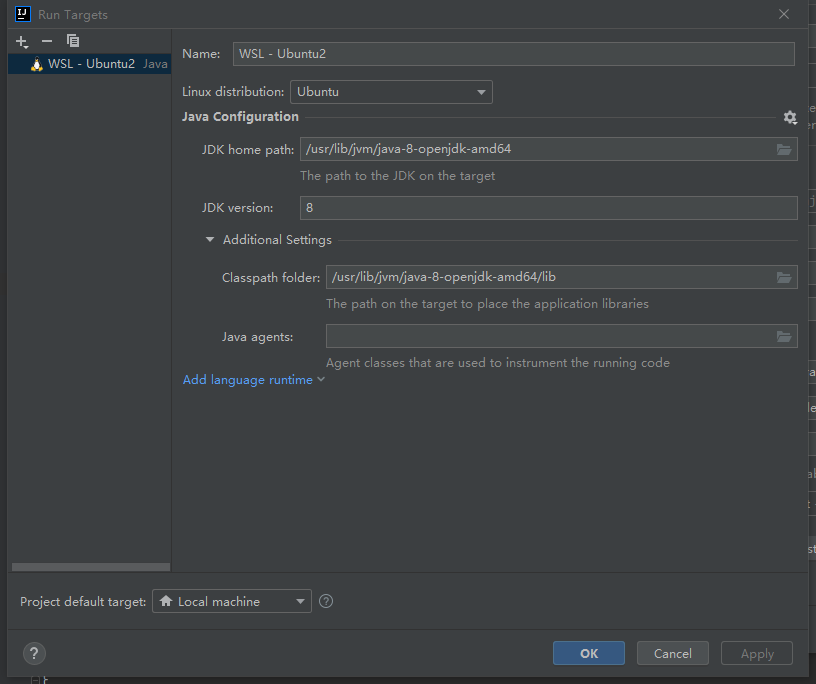
打开Run on选项将Local machine替换为WSL2:

此时应该就可以愉快的运行了。
需要注意的是你需要先将hadoop和ssh服务都开启才能正常运行,如何打开服务,请参考hadoop配置篇。
以下提供一个参考代码用于检测运行;
package com.jszszzy.test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.IntegerType
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("test")
.enableHiveSupport()
.getOrCreate()
}
}
对应的配置项如下,具体的信息需要你那个修改:
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.12.10"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-hive" % "3.1.3",
"org.apache.spark" %% "spark-core" % "3.1.3",
"org.apache.spark" %% "spark-sql" % "3.1.3"
)
lazy val root = (project in file("."))
.settings(
name := "test",
idePackagePrefix := Some("com.jszszzy.test")
)
当然你如果测试的时候出现以下错误,请按我的修改:
错误一
.assets%5C0-17.png)
Exception in thread "main" java.lang.IllegalArgumentException: System memory 462422016 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:221)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:201)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:340)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:189)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:277)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:458)
错误二
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:394)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2672)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:945)
at scala.Option.getOrElse(Option.scala:189)
这是因为JVM分配默认的内存有点小,并且我们没有设置运行的主节点,我们为其添加以下指令:
-Dspark.master=local[*] -Xmx3g
添加的位置如下:

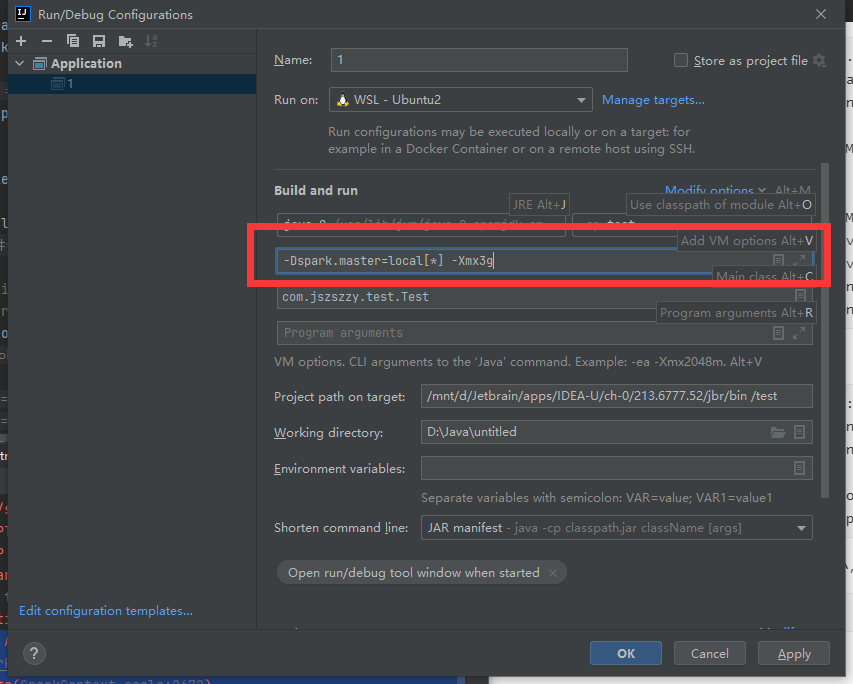
错误三
Hive支持失败。
ERROR ApplicationMaster:94 - User class threw exception: java.lang.IllegalArgumentException: Unable to instantiate SparkSession with Hive support because Hive classes are not found.
java.lang.IllegalArgumentException: Unable to instantiate SparkSession with Hive support because Hive classes are not found
问题不大请将sbt的依赖按照上文修改一摸一样即可,不要添加”provided“选项。
错误四
Command line is too long. In order to reduce its length classpath file can be used. Would you like to enable classpath file mode for all run configurations of your project? Enable
在stackoverflow上找到了解决办法:
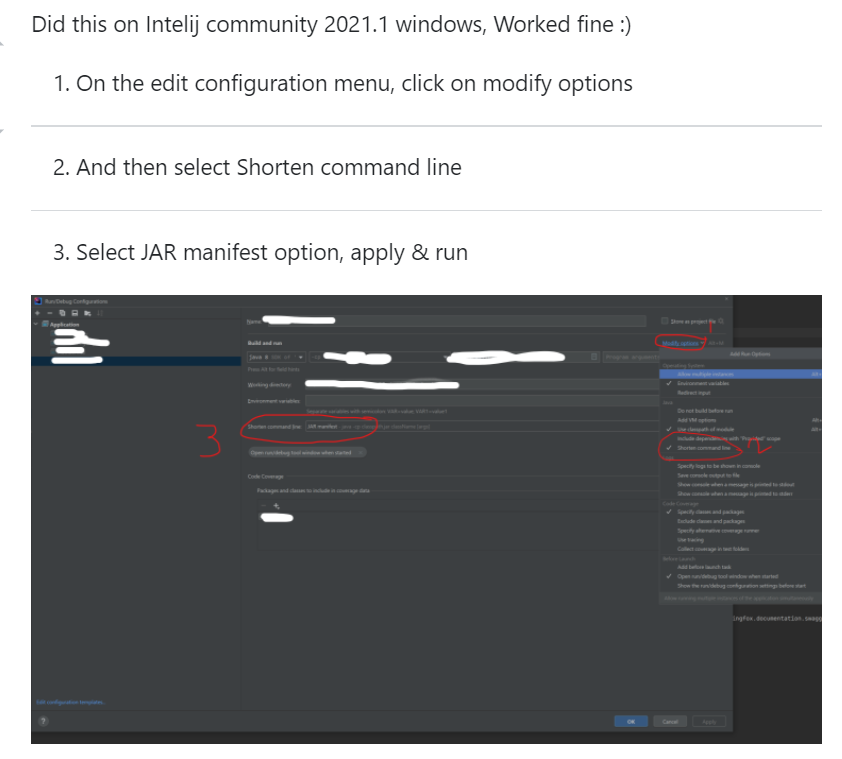
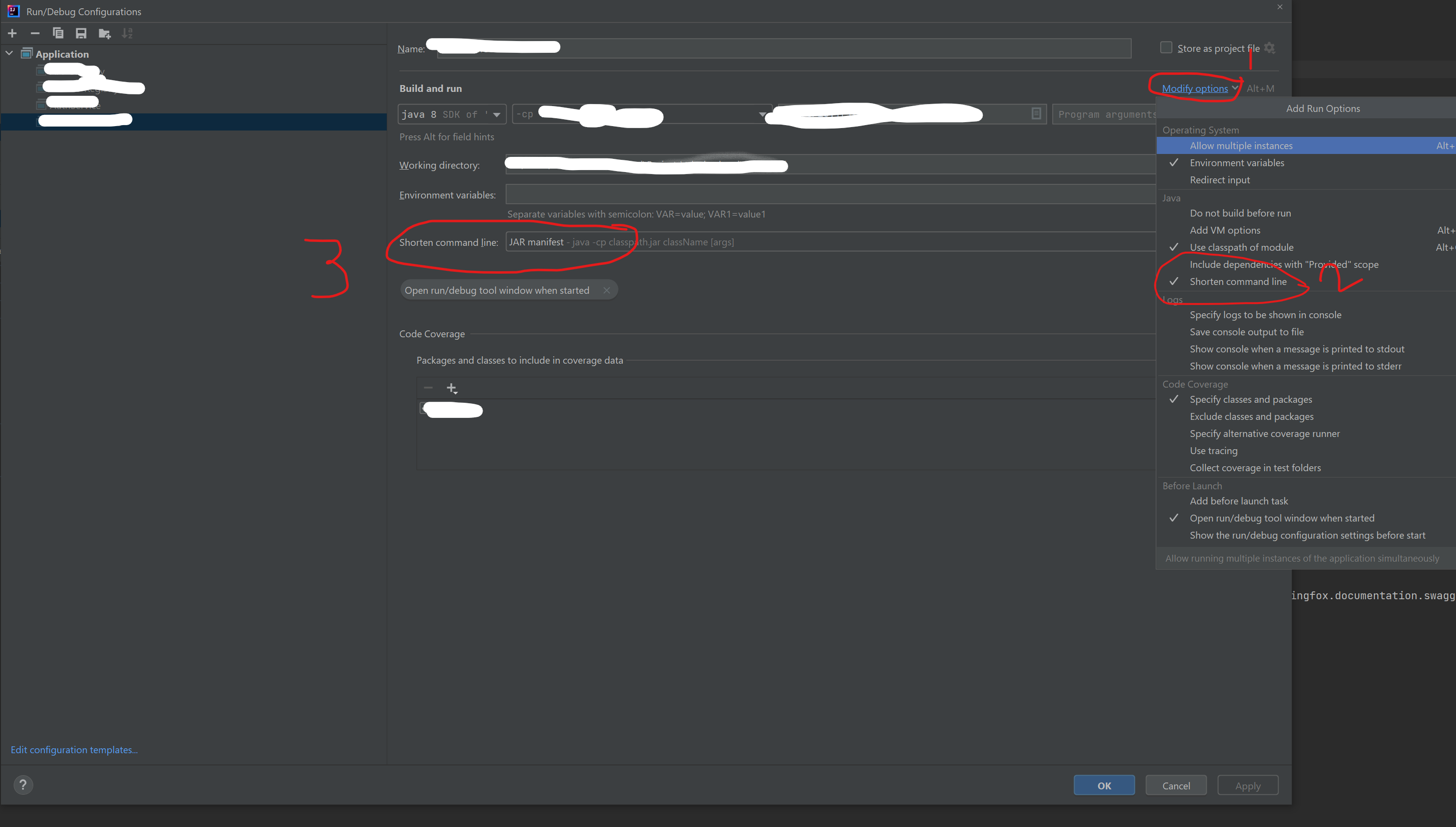
原回答链接:https://stackoverflow.com/questions/6381213/idea-10-5-command-line-is-too-long。