Spark快速大数据分析——Spark的结构化数据API(伍—分支1)
![[lab.magiconch.com][福音戰士標題生成器]-1727612689935](https://s2.loli.net/2024/09/29/ZRGWD1Vcf9L7T8a.jpg)

[TOC]
软件环境:
强烈提示:
请按照对应配套版本来进行环境配置!
- Hadoop-3.2
- IDEA 2021.3.2
- Spark-3.1.3 搭配 scala版本:2.12 构建方式:IDEA导入本地JAR,Spark库
- JDK 8
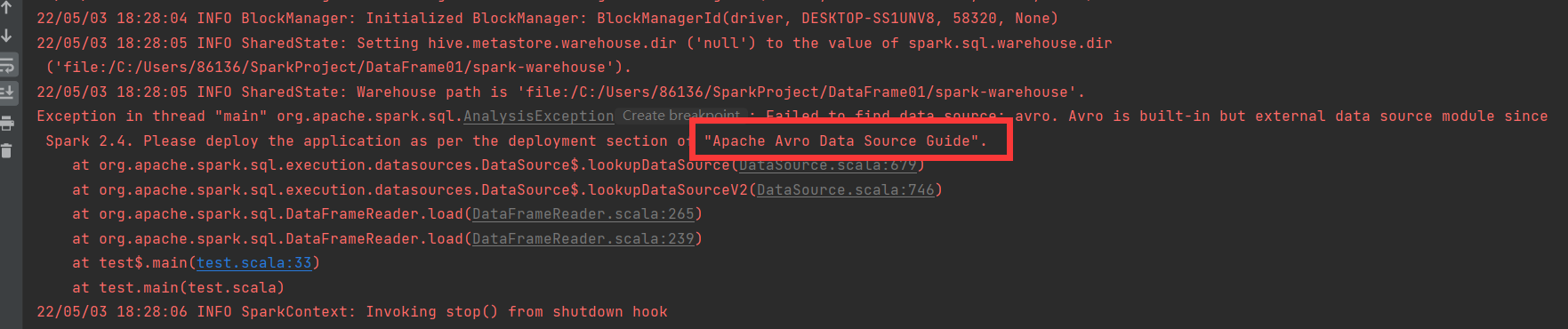
Spark读取AVRO数据报错
22/85/83—18:28:84 INFD BlockWanager: Initialized BlockWanager: BlockHlanagerId(driver,DESKTOP-S-1UNV8,58320,None)
22/85/8318:28:05 TIFO ShanedState: Setting hive.metastore .warehouse.dir ('null' ) to the value of spank.sq1.wavehouse.dir( 'file:/C:/Users/86136/SparkProject/DataFrame01/spark-warehouse').
22/05/83 18:28:05 INFD ShanedState: Warehouse path is 'file:/C:/Users/86136/SparkProject/DataFrame1/spark-warehouse .
Etneptio in thrcadt"rsin" ng .apacne .span.go..nlysisExceaptin Cestetorghmit. laild tn find dota Lcauow av. Akn is built-in but extenal data sounce moduvle sine8Spark 2.4.Please deploy the application as per the deployment section o "Apache Avro Data Source Guide".
at org.apache .spark.sql.execution.datasources.DataSource$.lookupDataSoUrce(Uata8Ource.scala.6797)
at org.apache .spark.sql.execution.datasoucces.DataSource$.lookupDataSourceV2(DataSounce.scala:746)at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:265)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:239)at test$.main(test.scala:33)
at test.main(test.scala)
22/05/03 18:28:06 INF0 SparkContext: Invoking stop() from shutdown hook
在使用IDEA的构建模式下,我该如何导入AVRO包来实现AVRO的数据读入呢?
首先,在windos下打开CMD或者Powershell
输入以下命令:
spark-shell —packages org. apache.spark:spark-avro_2.12:3.1.3 ...
首先要确认你安装了Sparkshell,并能正确运行和我上边的配置版本基本相同,因为不同版本的这个包是不通用的。
运行以后结果如下:

等着出现Sparkshell的标志既可。
需要注意的是不要急着关闭,要记录一个关键信息:

下载的jar包的存储位置。
我们找到找个jar包的位置并把它复制到IDEA导入的Spark的jar路径。
名字其实不太需要修改,我这边使用的没有问题。
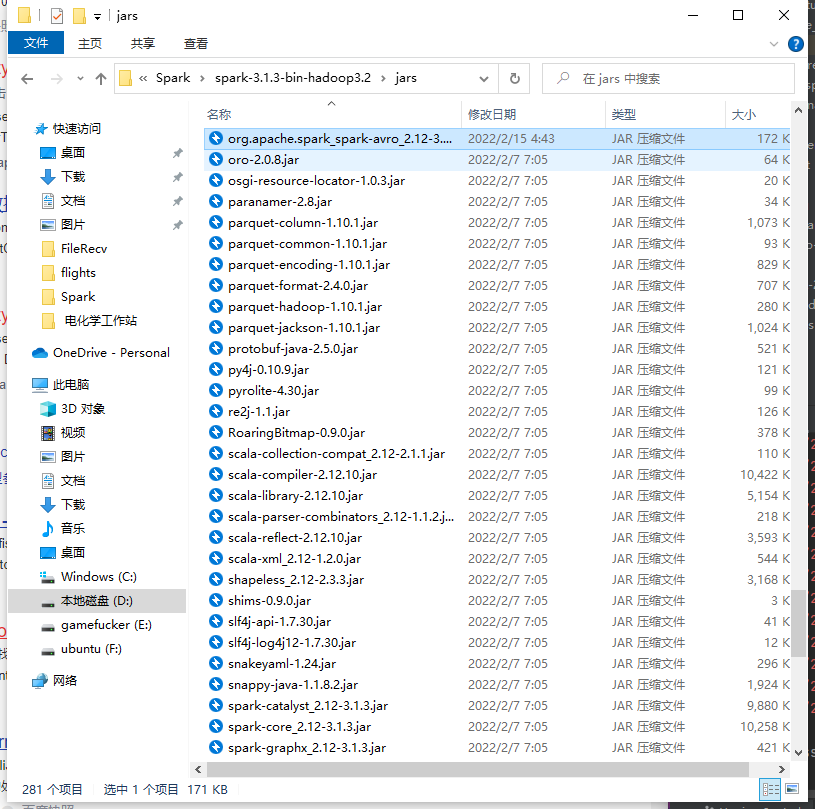
最好在文件再导入一下依赖:
import org.apache.spark.sql.avro.functions._
但是我这边测试的时候只要加入到spark的jars包里面就可以了,看具体情况吧。