Spark快速大数据分析——Spark的结构化数据API(伍)
![[lab.magiconch.com][福音戰士標題生成器]-1727612573373](https://s2.loli.net/2024/09/29/2FrYNJepTGxCiEs.jpg)

[TOC]
软件环境
强烈提示:
请按照对应配套版本来进行环境配置!
- Hadoop-3.2
- IDEA 2021.3.2
- Spark-3.1.3 搭配 scala版本:2.12 构建方式:IDEA导入本地JAR,Spark库
- Spark-3.2.1 搭配 scala版本 :2.13.8 构建方式 :SBT自动导入依赖
- JDK 8
Spark的结构化数据API
Spark在1.x版本中首次引入了Spark SQL,Spark SQL 引入了表达能力更强的高层操作函数模仿类似于SQL的语法,接着Dataframe作为SchemaRDD的继任者由Spark1.3引入,为后续版本中更多的结构化支持打下了基础,并为Spark查询计算中的高性能操作做铺垫。
RDD(Resilient Distributed Datasets)弹性分布式数据集
在结构化数据API诞生之前,Spark都是使用RDD来完成操作的,首先来讨论一下什么是RDD?
RDD是Spark最基本的抽象。存在三个至关重要的属性:
- 依赖关系
- 分区
- 计算函数:Partition => Iterator[T]
这三大属性对于简单的RDD编程API模型来说都是不可或缺的,其他的更高层的功能也给予这三种属性构建。
依赖关系就是上一节所说的血缘,通过依赖关系列表会告诉Spark如何通过输入来构建RDD,同时需要重算的时候Spark可以根据这些依赖关系重新执行操作,重建出RDD。这一属性赋予了RDD容错的弹性。
分区指的是Spark工作的时候以分区为单位,分配到多个执行器上并行运算,再某些情况下如使用HDFS读取信息,Spark会使用分区信息来判断位置远近,这样一来,需要跨网络传输的带宽就少了很多。
最后每一个RDD都需要一个计算函数compute,可用于生成RDD所表示数据的Iterator[T]对象,实际上就是计算完成后的结果。
RDD存在的问题
RDD传输的计算函数对于Spark来说是不透明的,也就是说Spark不知道你在计算函数里面要干什么。无论是要做连接、过滤、还是聚合,Spark是没有办法具体了解你的传输的lambda表达式具体的操作,实际上让Spark推断的话是很困难的一件事。
这就无法实现前文针对执行计划来做出优化的方式,因为Spark根本不知道你在做什么。无法针对你的具体执行操作来实现优化。
其次是Iterator[T]对象对于Spark来说也是什么都不知道,拿Python的RDD来说,Spark只知道这是一个python的对象,这样就造成了另一个问题。
Spark无法针对数据类型来对数据进行压缩等操作,只能将其不透明的对象转化成字节码传输。
Spark的结构化数据
针对Spark存在的问题,Spark在2.x版本引入了用于支持结构化数据的方案。其中之一就是为了解决数据操作不透明的问题而诞生的顶层API。
通过引入数据分析常用的模式来表达计算。这些模式使用过滤、选择、计数、聚合、平均和分组等高层操作来进行表示。这样一来,计算的表达更加清晰、简洁了。
通过在DSL(领域特定语言)中使用通用的算子,可以进一步减少计算表达的特异性。Spark所支持的语言都提供了这样一组算子,这些算子让你能够告诉Spark希望计算出来什么数据。这样一来,Spark能够以此为依据为实际执行构建出高效的查询计划,并最终执行。
结构化的关键点与好处
我们首要讨论的就是:
结构化的优点:表达能力强、简洁、易组合、风格一致。
举个例子:
以下是配套书的代码并未尝试运行,如有错误请以书为准。
#Python代码
#创建二元组(nare,age)构成的RDD
dataRDD = sc.parallelize([("Brooke",20),("Denny",31),(" Jules",30),("TD",35),( "Brooke",25)])
#调用转化操作rap和reduceByKey,借助lanbda表达式来聚合并计算平均值
agesRDD = (dataRDD
.map(lambda x: (×[0],(×[1],1)))
.reduceByKey( lambda x, y: (×[0] +y[0],x[1] + y[1]))
.map( lambda x: (×[0],x[1][0]/x[1][1])))
可以看到实际操作都是使用map等底层数据api通过传入lambda表达式来实现的具体操作,不仅表达能力、可读性差而且跨语言实现起来相同的操作会因为不同语言的语法而导致存在很大的差异,比如使用Scala来实现就完全不相同。
如果使用DataFrame(结构化)呢?
#Python代码
fron pyspark.sql inport SparkSessionfron pyspark.sql.functions import avg#用SparkSession创建DataFrame
spark = (SparkSession
.builder
.appNane( "AuthorsAges")
.getOrCreate())
#创建DataFrame
data_df = spark.createDataFrane([("Brooke" ,20),( "Denny",31),(" Jules",30),("TD",35),( "Brooke",25)],[ "name" , "age"])
#按名字分组,聚合同名人的年龄,计算平均值
avg_df = data_df.groupBy( "name" ).agg(avg( "age" ))
avg_df.show()#展示执行的最终结果
跟上一个版本比相比,你应该在没学过的情况下也能大概推断出这一部分代码是干什么的,实际上我们已经通过这些API明确告诉了Spark该去做什么,所以Spark能针对你写的代码进行优化或者重排整体操作被API组合成了一条链式调用。
高度封装API会导致开发者的应用受限不自由,这是经常发生的事情,你在初学Spark的时候就有可能会遇到(使用的不自在),但是目前咱先把这个问题放一放,因为Spark同时支持你使用上边的底层API和高层API混写。
DataFrame API
Spark的DataFrame API可以说就是将Pandas库抄过来的,同样是结构化,有格式的,且支持一些特定的操作,就像分布式内存中的表那样,每一列都有名字,每张表都需要通过表的定义来设置数据类型,整型,字符串或者实数等,就单纯来说Dataframe对于人来说就是张表,表头就是表的定义。
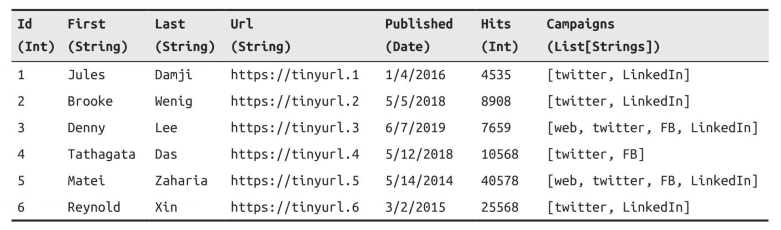
Spark的基本数据类型
Spark的基本数据类型都与对应的内部数据类型,**这些数据类型既可以通过Spark应用来定义,也可以在Spark的表结构来定义。**使用Scala编写代码的时候可以直接将某列的定义声明为String,Byte,Long等。
举个例子:
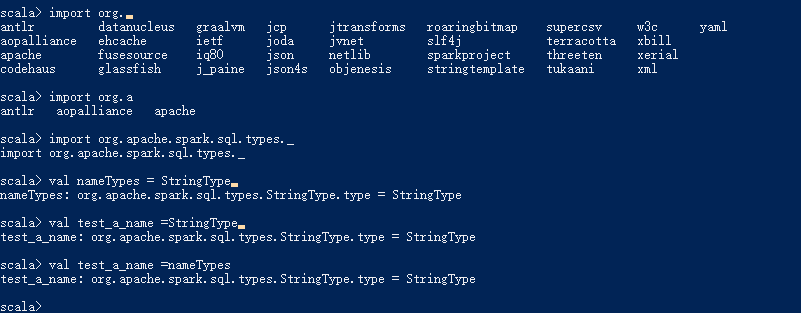
可以看到使用了一个 类型是StringType的变量
注意的是这里使用的实际上是他的构造方法创建的对象,并不是Scala的类型定义的方式所以是=号,而这里实际上是将变量绑定到对应spark中StringType的一个叫type的成员类型,并不是真正的字符串。
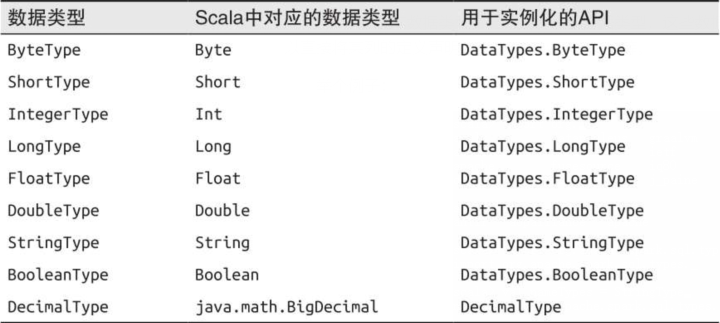
Spark的复杂数据类型
复杂的数据分析不会只有简单的数据类型。有些时候需要格式化,标准化数据类型来作辅助,原数据可能是随意记载的,比如日期,每个人记录格式不统一就需要使用一种标准化的数据类型来将读入数据统一一下。当然还有些数据结构用来构建Dataframe,比如:映射表、数组、结构体。
下表展示了Spark支持的结构化数据类型:

如果你对Seq或者Map不太熟悉请查看关于scala数据结构的内容。