Spark快速大数据分析——Spark的安装与介绍(壹)
![[lab.magiconch.com][福音戰士標題生成器]-1727611659085](https://s2.loli.net/2024/09/29/TZ9xIe13HbgNAOn.jpg)

软件环境:
- Hadoop-3.3.2
- Spark-3.1.3/Spark-3.2.1(sbt pull)
- JDK 11
- Scala 2.13.8/SCala 2.1(搭配3.1.3使用)
[TOC]
Spark介绍
来自美国加州大学伯克利分校、具有 Hadoop MapReduce 经验的研究人员接受了挑战, 并推出了 Spark 项目,2009 年,Spark 项目在 RAD 实验室诞生,后来该实验室改名为 AMPLab(现在名叫 RISELab).
Spark 项目的中心思想是,借鉴 Hadoop MR 的思想并增强系统,加上高容错性和高并发, 支持将迭代式或交互式映射和归约计算的中间结果存储在内存中,并向用户提供支持多种 语言、简单、易组合的 API 作为编程模型,一站式支持各种使用场景.
2014 年 5 月,在 Apache 软件基金会的管理下,Databricks 与开源社区的开发人员共同 发布了 Apache Spark 1.0。
Spark 为中间计算结果提供了基于内存的存储,这让它比 Hadoop MR 快了很多,它整合 了各种上层库,比如用于机器学习的库 MLlib、提供交互式查询功能的 Spark SQL、支持 操作实时数据的流处理库 Structured Streaming,以及图计算库 GraphX,这些库都提供 了易用的 API。
Spark 的设计哲学围绕下列四大特性展开:
⚫ 快速 ⚫ 易用 ⚫ 模块化 ⚫ 可扩展
环境搭建:
首先下载Spark:Spark下载地址
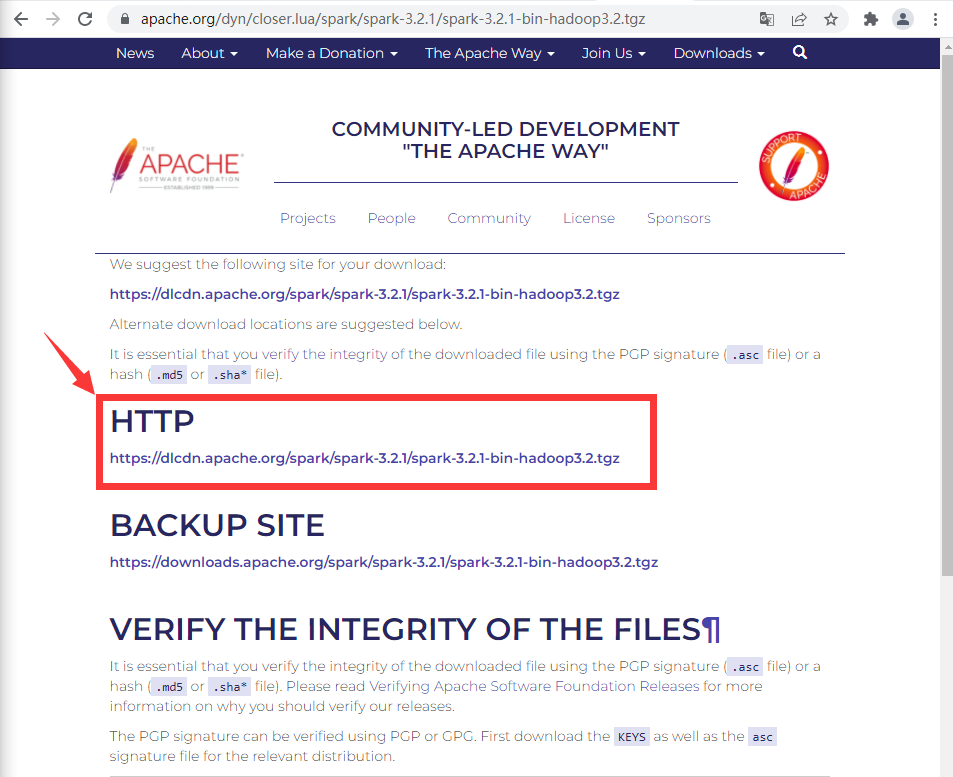
点击下载Spark,如果你网速慢也该可以通过我的gitee来下载。gitee地址:
下载后直接解压即可:
我解压位置如下
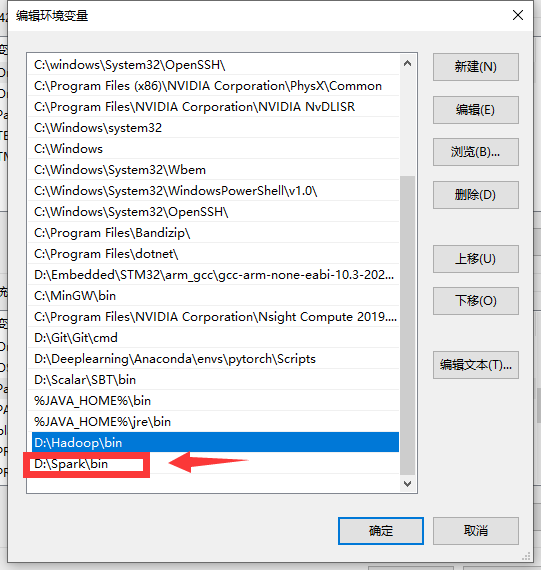
然后添加系统环境变量:
spark的运行需要Hadoop的支持,所以还需要下载Hadoop来支持运行:
也是压缩包需要注意的是解压需要提供管理员权限。
解压完后添加环境变量和系统变量。
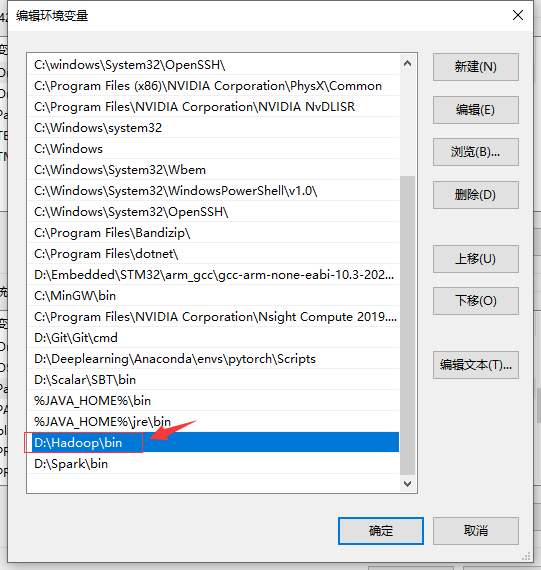
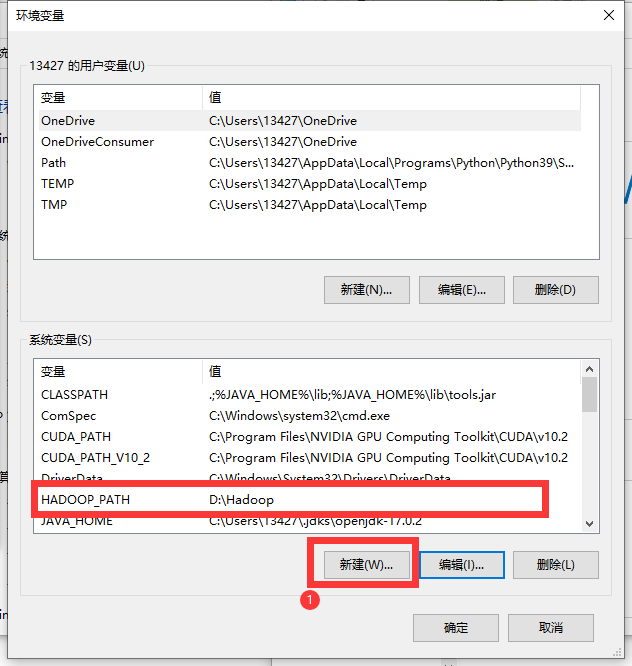
新建一个系统变量:
到这里还没有完,如果你是win环境下开发可能会遇到报错:
C:\spark-3.2.0-bin-hadoop3.2\bin>spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/11/11 00:14:24 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
21/11/11 00:14:26 ERROR SparkContext: Error initializing SparkContext.
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.spark.executor.Executor.addReplClassLoaderIfNeeded(Executor.scala:909)
at org.apache.spark.executor.Executor.<init>(Executor.scala:160)
at org.apache.spark.scheduler.local.LocalEndpoint.<init>(LocalSchedulerBackend.scala:64)
at org.apache.spark.scheduler.local.LocalSchedulerBackend.start(LocalSchedulerBackend.scala:132)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:220)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:581)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2690)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:949)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:943)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:106)
at $line3.$read$$iw$$iw.<init>(<console>:15)
at $line3.$read$$iw.<init>(<console>:42)
at $line3.$read.<init>(<console>:44)
at $line3.$read$.<init>(<console>:48)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.$print$lzycompute(<console>:7)
at $line3.$eval$.$print(<console>:6)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
但没关系,我帮你踩坑了~
只需要按照对应版本进行下载然后替换bin目录下的内容即可:
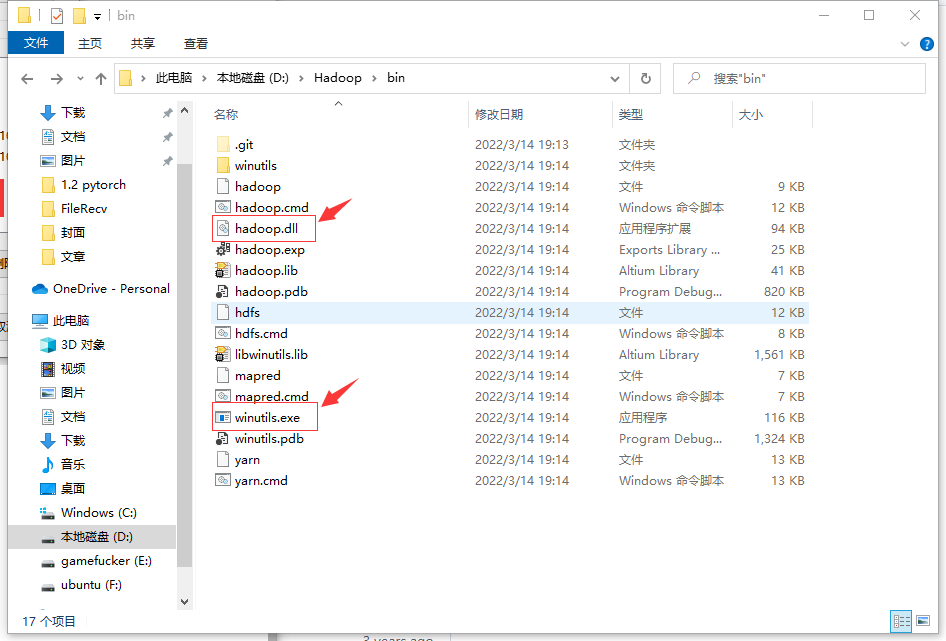
在任意地方打开cmd:
输入 spark-shell。等待一会:
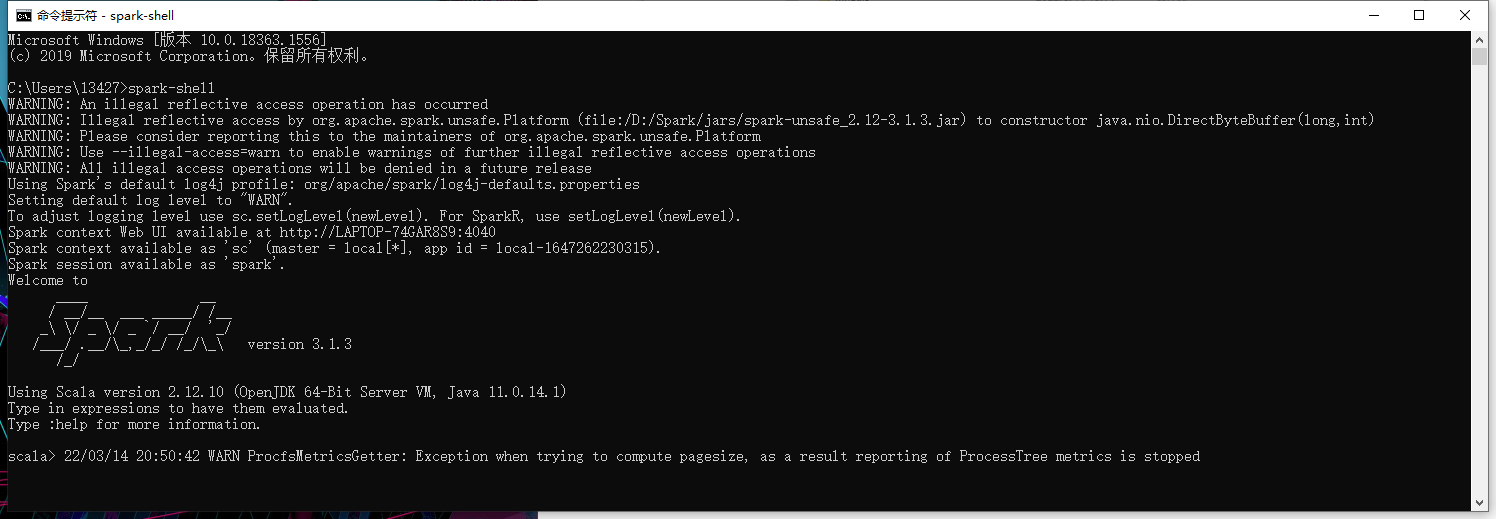
引用一个库看一看:
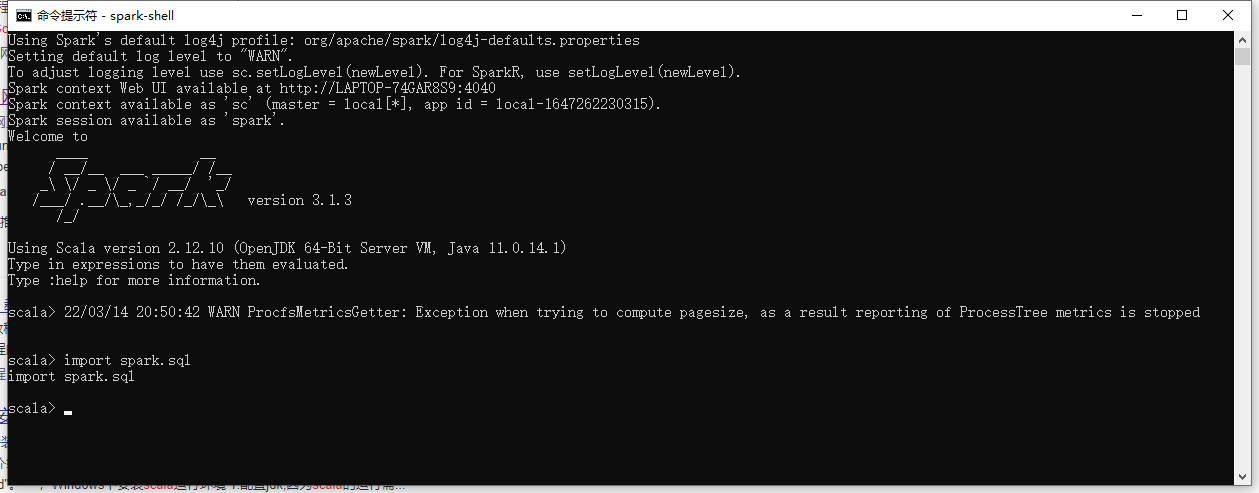
如果正常恭喜你完成了80%,这些都是基于命令行的,可是我们要基于IDEA要怎么开发呢?
首先idea支持的构建方式首选的是SBT,如果你没有安装sbt可以参考上一篇文章:。
打开IDEA新建一个项目:
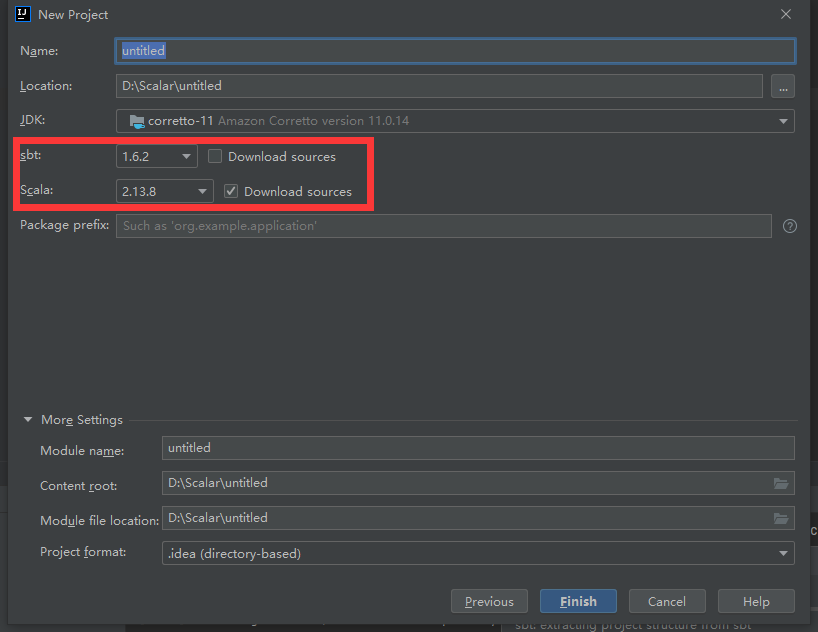
系统会自动检测你的安装的SBT和SCALA
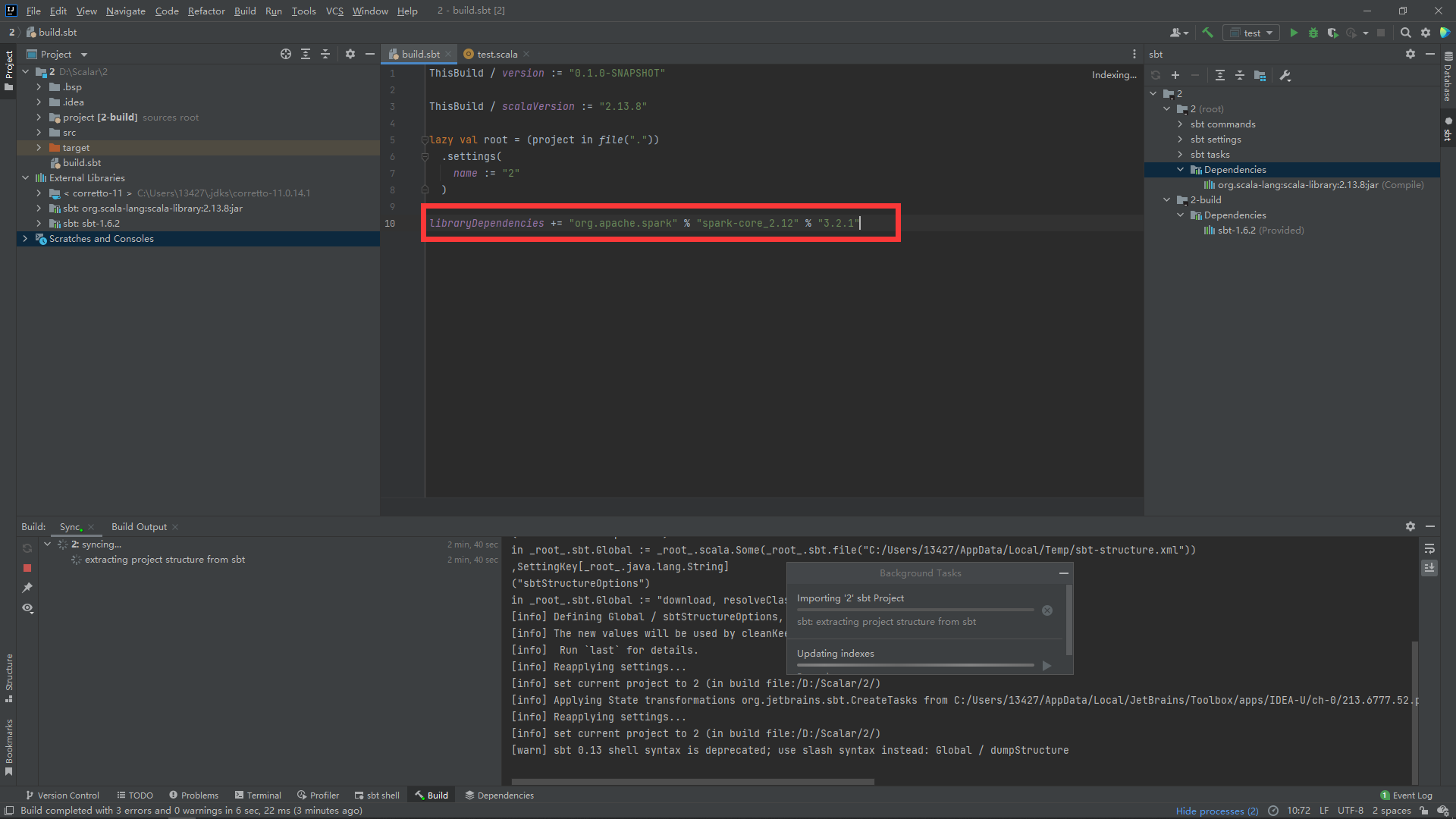
在创建完成后在build.sbt中添加如下代码:
libraryDependencies += "org.apache.spark" % "spark-core_2.12" % "3.1.3"
如果你在MVN找到的sbt依赖添加代码是这样的:
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.1.3"
或者是这样的:
libraryDependencies += "org.apache.spark" % "spark-core" % "3.1.3"
//这个是错的 %% 才能自动指定scala版本
有可能会报错:
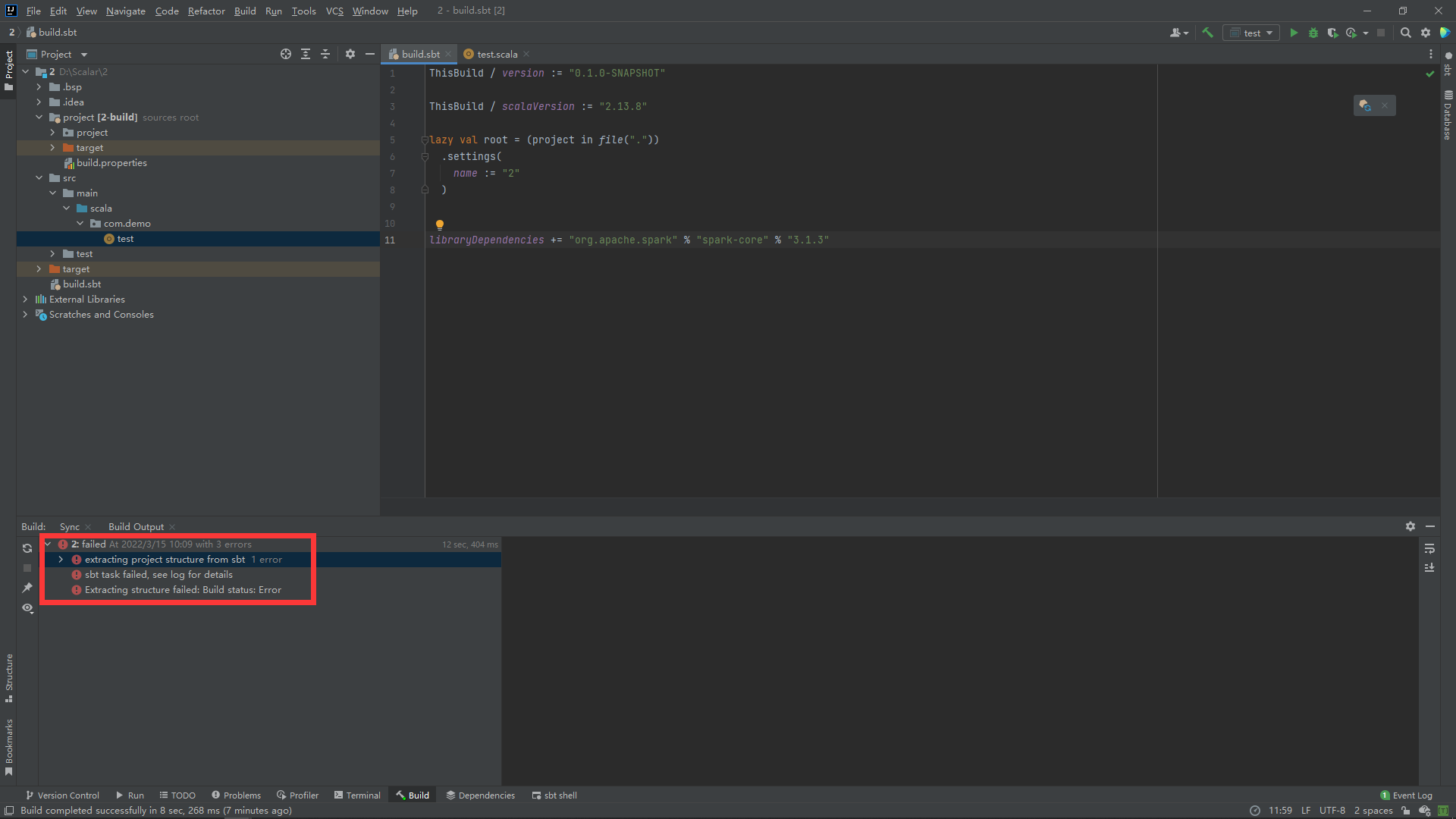
没关系更改一下版本就可以:
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.1"
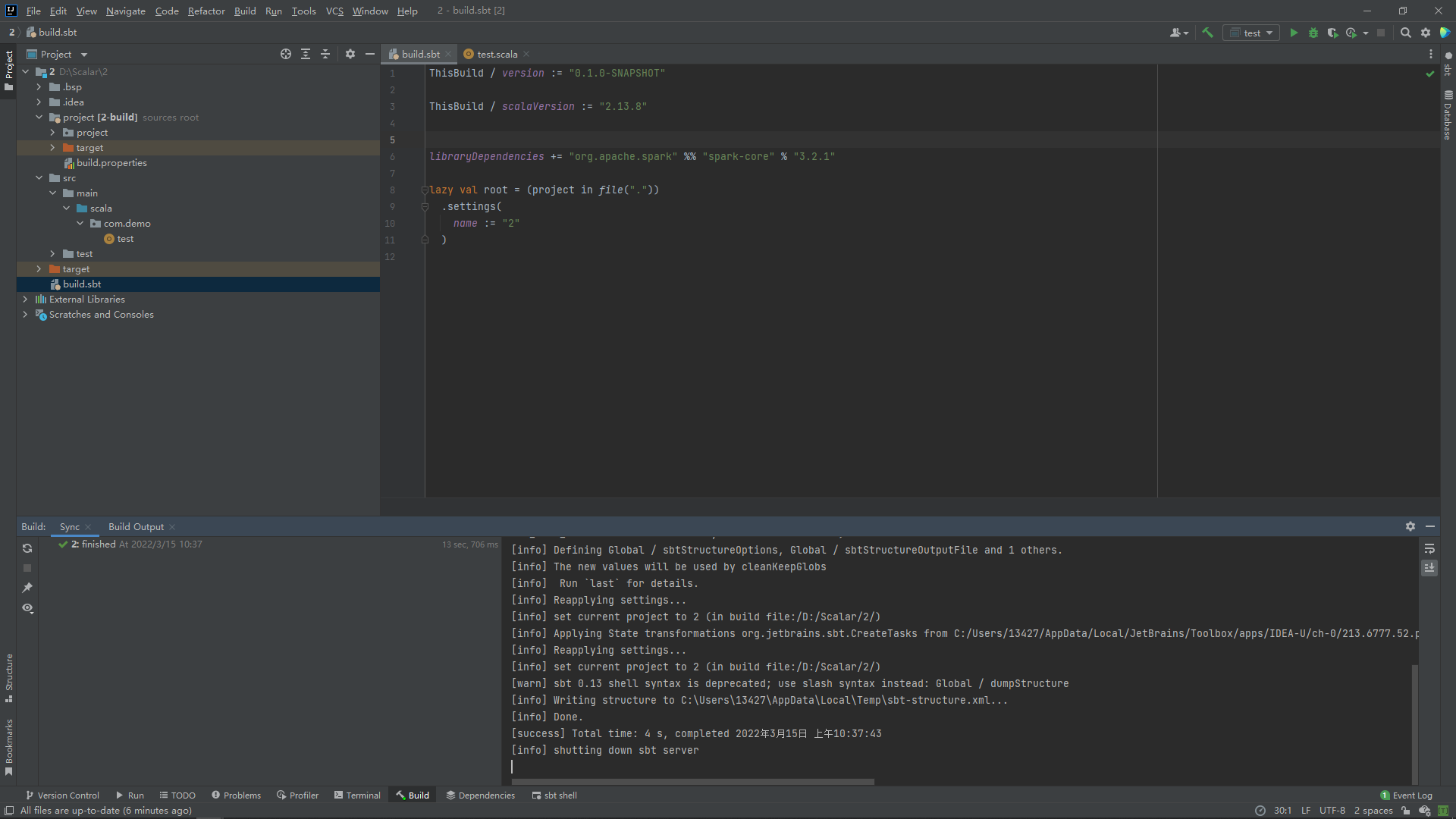
如果更改版本还没办法的话可以指定一下版本:
libraryDependencies += "org.apache.spark" % "spark-core_2.12" % "3.1.3"
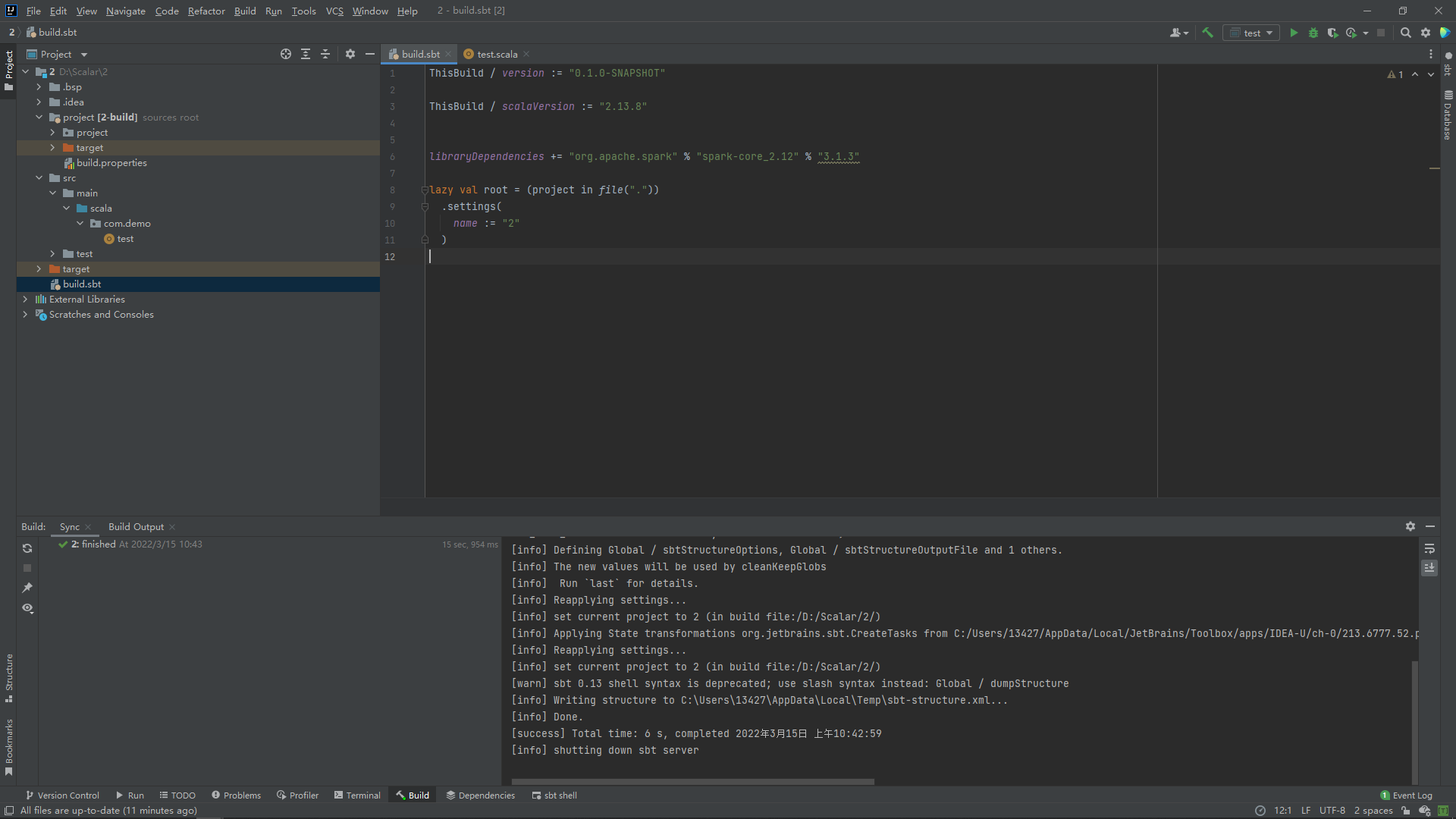
但是你如过不太清楚构建spark的scala和你本地的scala是否匹配的话建议还是用“%%”来自动匹配版本:
否则就会报错:
Exception in thread "main" java.lang.NoSuchMethodError: 'void scala.util.matching.Regex.<init>(java.lang.String, scala.collection.Seq)'
at scala.collection.immutable.StringLike.r(StringLike.scala:284)
at scala.collection.immutable.StringLike.r$(StringLike.scala:284)
at scala.collection.immutable.StringOps.r(StringOps.scala:33)
at scala.collection.immutable.StringLike.r(StringLike.scala:273)
at scala.collection.immutable.StringLike.r$(StringLike.scala:273)
at scala.collection.immutable.StringOps.r(StringOps.scala:33)
at org.apache.spark.util.Utils$.<init>(Utils.scala:105)
at org.apache.spark.util.Utils$.<clinit>(Utils.scala)
at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:75)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:70)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:59)
at com.demo.test$.main(test.scala:8)
at com.demo.test.main(test.scala)
这里给一段测试代码,如果报错了你就要更换spark版本:
package com.demo
import org.apache.spark.{SparkConf, SparkContext}
object test
{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("HelloWorld")
val sc = new SparkContext(conf)
val helloWorld = sc.parallelize(List("Hello,World!","Hello,Spark!","Hello,BigData!"))
helloWorld.foreach(line => println(line))
}
}
如果没问题,环境就搭建好了!
但是你会有个疑问:
为什么我都本地下载了Spark,还需要下载托管的Spark?
这是我刚开始的疑问,SBT不能同时管理本地的jar包吗?必须重新下载后才能管理本地内容吗?
通过SBT手动添加JAR包是可以的,但是有点复杂 而且需要添加多个才能使用,所以这里推荐另一个模式来构建项目:
我们来利用IDEA本身的管理来构建Scala项目,在创建栏选择IDEA:
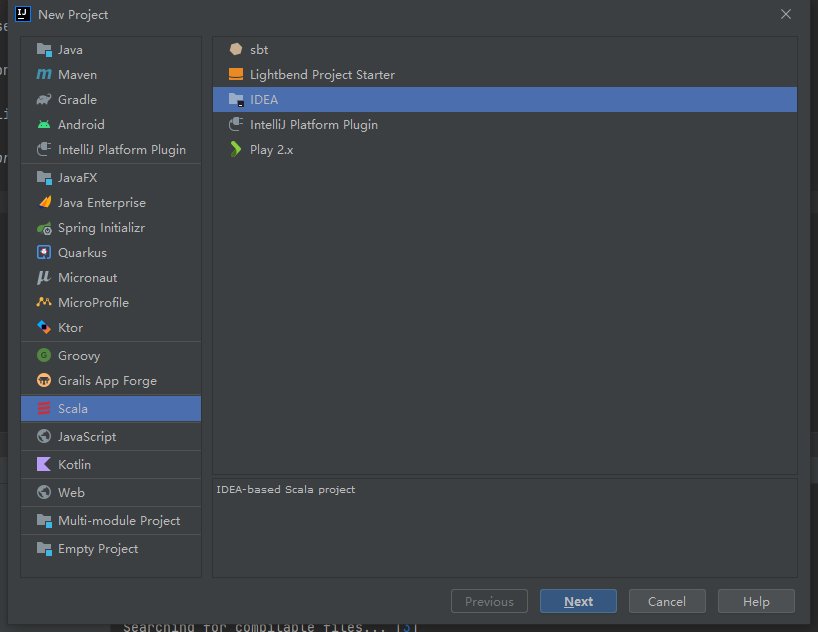
后面都是一样的,这里主要讲解一下如何导入本地Spark实现项目构建:
选择对应选项卡:
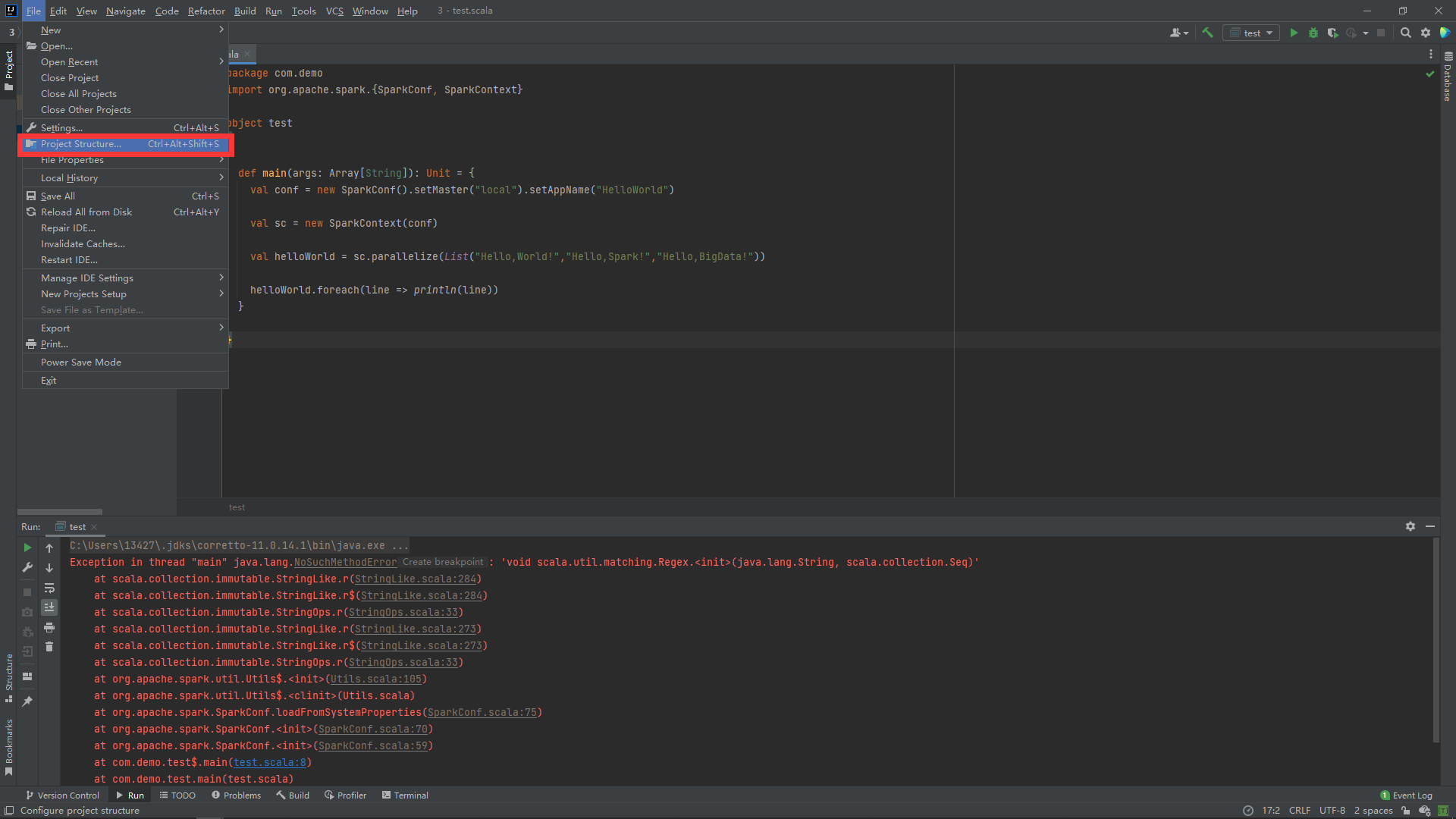
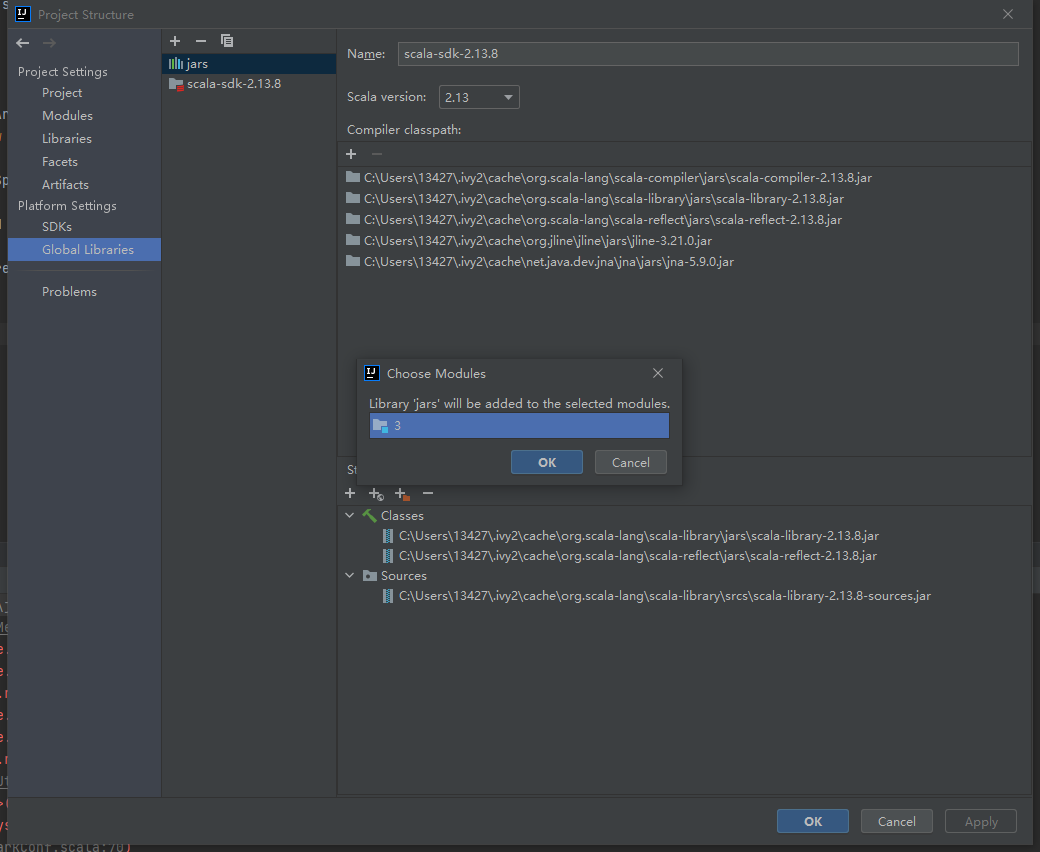
在Golobal Libraries用+添加Spark:
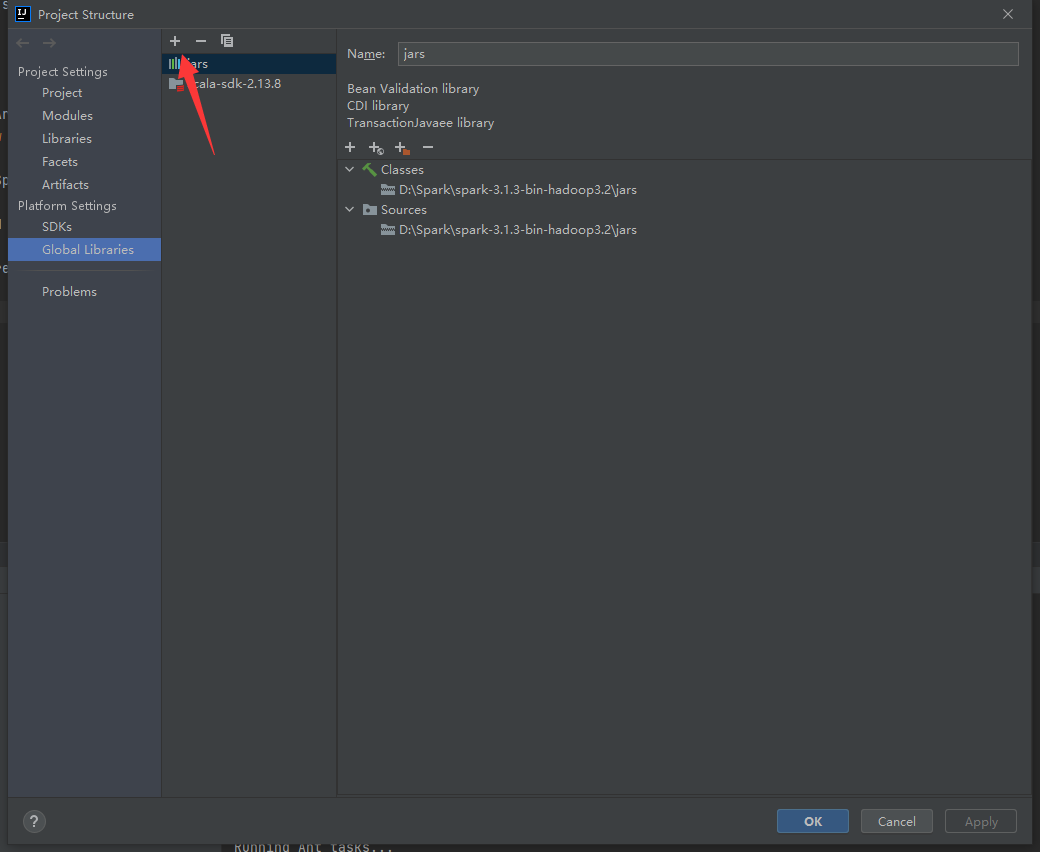
选择java选项:
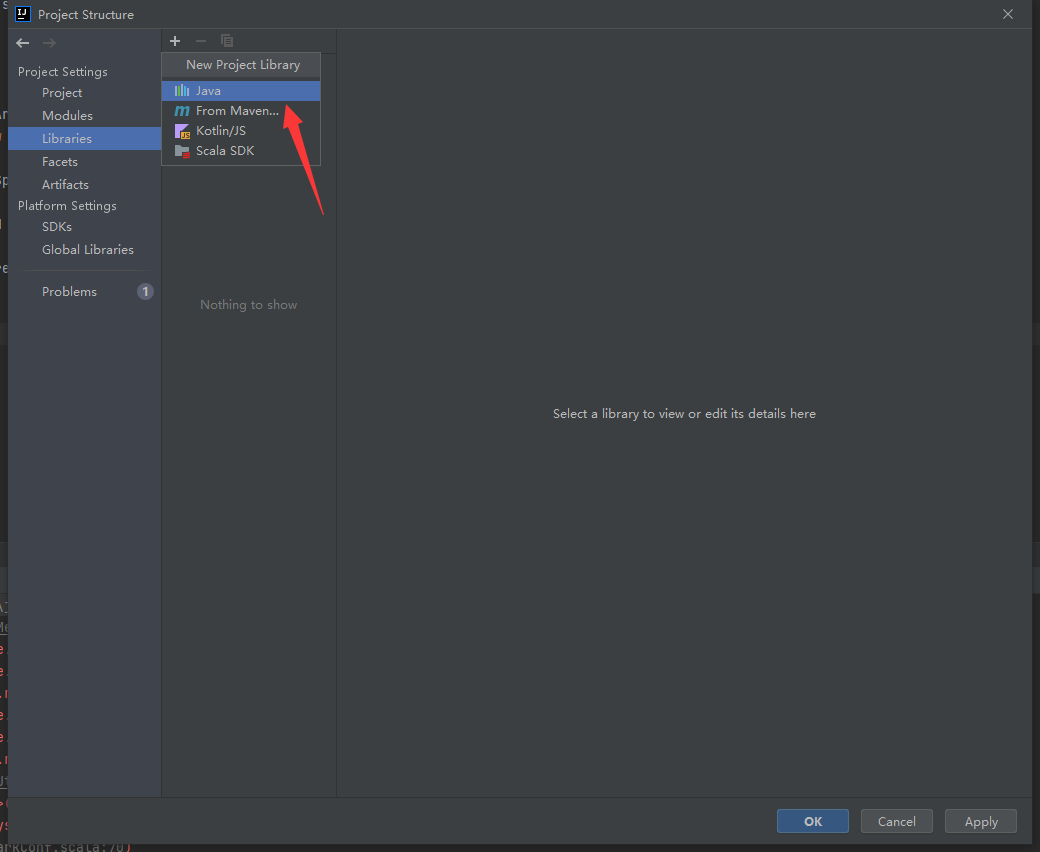
找到自己Spark安装的:
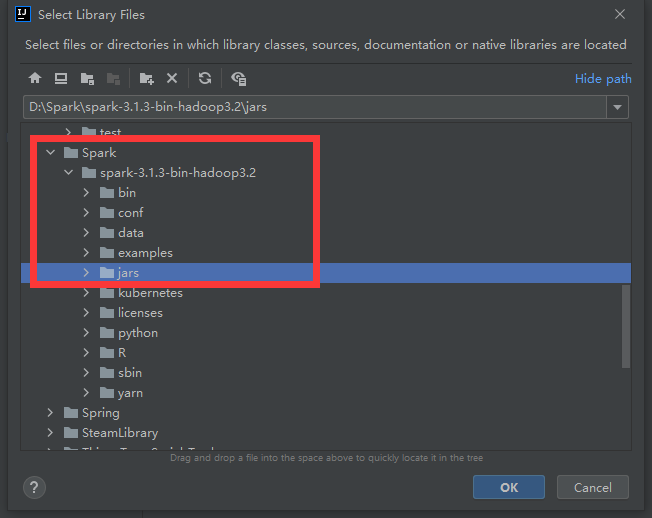
点击OK:
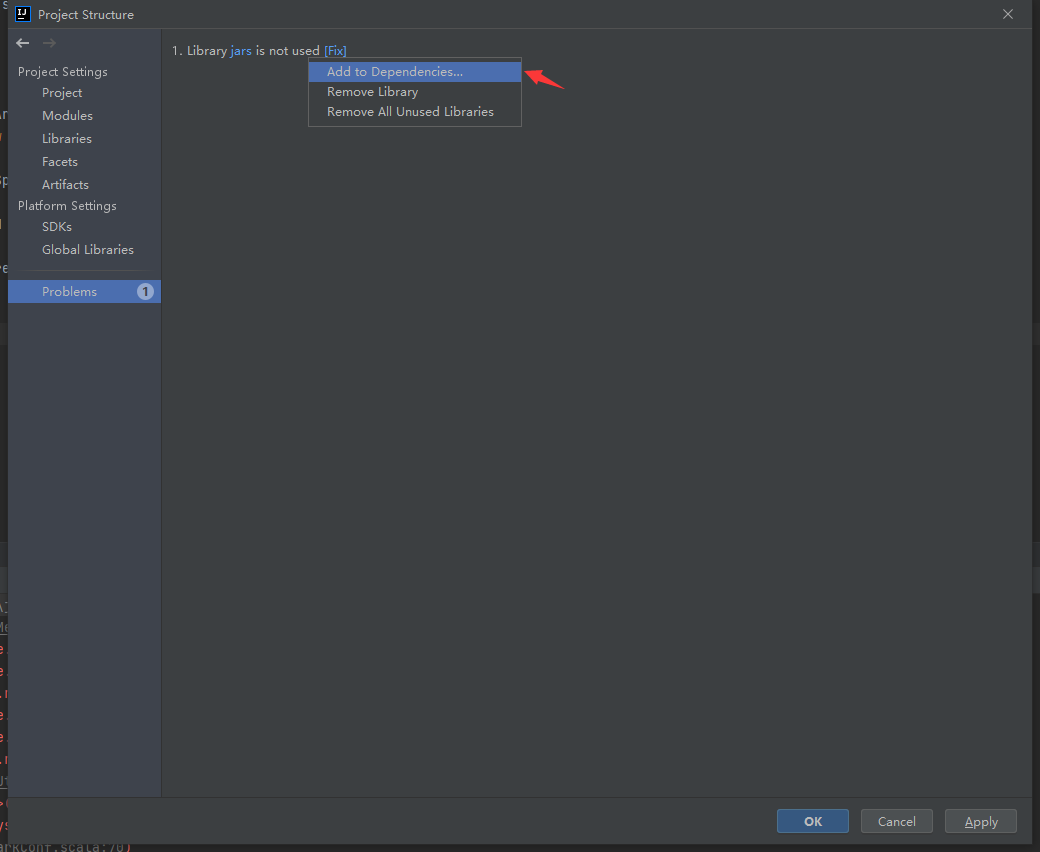
如果出现Problems点击一下Fix,选择添加到依赖修复即可:
在外部库中可以看见jars,并且可以引用Spark: