BionetServer-No1使用说明-进阶(Docker方式)
![[lab.magiconch.com][福音戰士標題生成器]-1727547630579](https://s2.loli.net/2024/09/29/qWjluktz8hxAV4E.jpg)

Version:1.3
Docker篇更新记录:
- 添加了常见错误解决方案
- 添加了复制容器使用说明
- 修改了镜像使用指南
- 删除了R部分内容,将在下一个版本重构R说明
Date: 2025.9.24
Authors:魏持之,NeoNexus
[TOC]
开发的最佳实践
开发的最佳实践基于Docker来实现,使用Docker已经成为世界上最重要和流行的开发模式,学习如何使用Docker来进行开发,不管你走到哪里,是科研还是进入互联网大厂,这一套开发方式的部署会让你受益无穷。下面将简单介绍一些基础概念,由于篇幅限制,介绍的不是很详细,但能帮你有一个初步的了解。
使用Docker的优势:
- 便于使用者管理环境
- 快速在多台部署有Docker基础环境的机器上运行对应程序,可以在不同的机器中迁移运行,无需重复调整开发环境。
- 支持集群部署
- root权限
- 高性能,容器部署30s内即可完成
第一次查看此文档建议按照顺序看,第一创建成功之后建议使用模板方法快速创建。
Docker的使用与创建
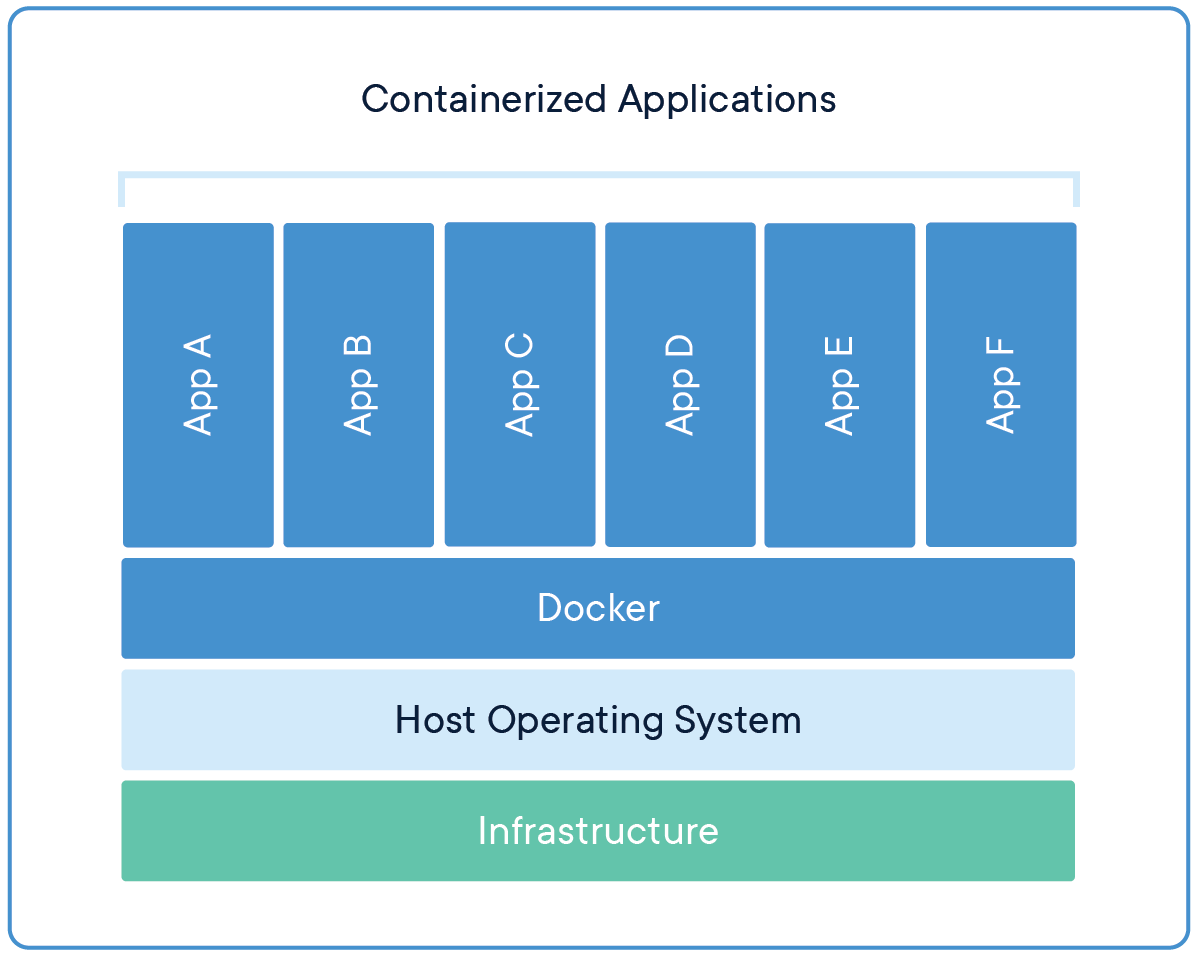
下图展示了Docker的基本运行原理,其运行在一个基本的操作系统上,并在一个Docker支持多个运行的基本环境。
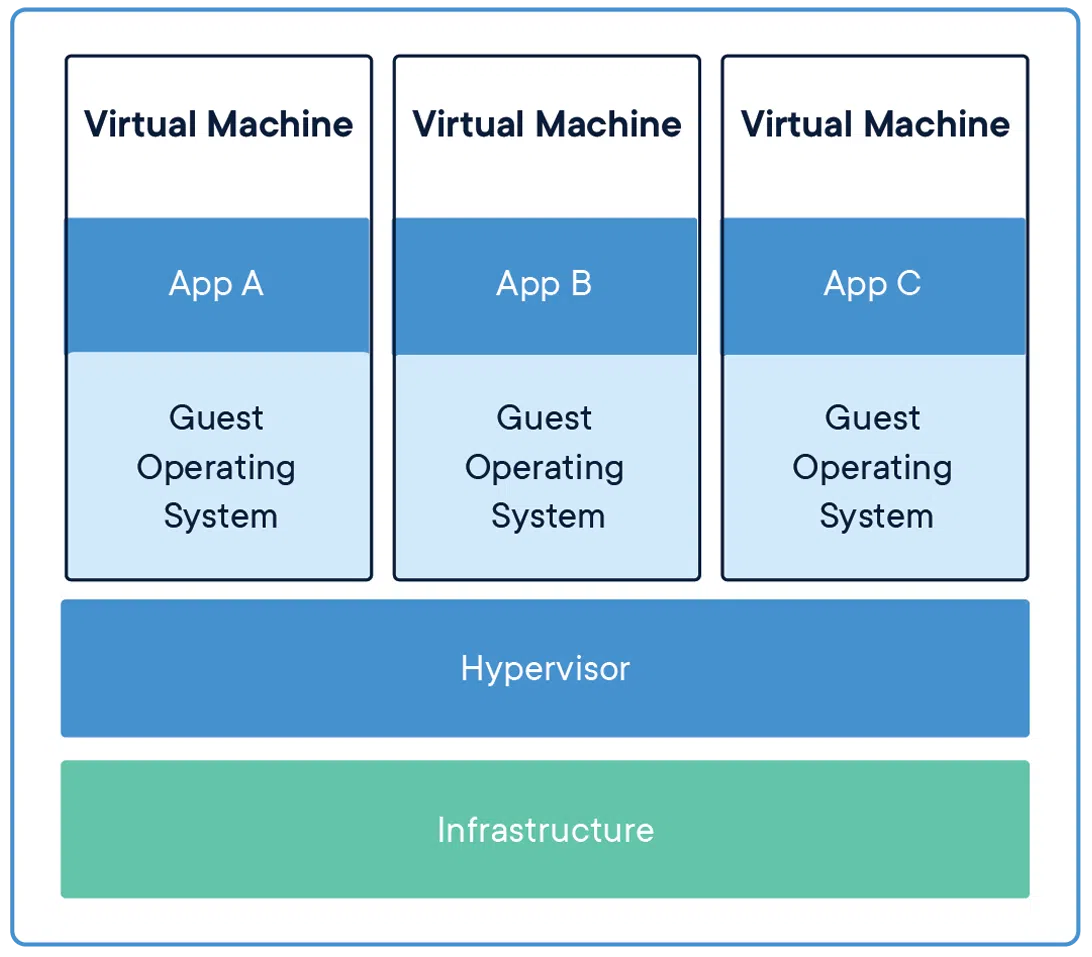
下图展示了传统的VM(虚拟机)架构,是运行在硬件的抽象层之上的,并且每一个虚拟机都有一个操作系统的支持,就是对应的Guest Operating System。
开发的最佳实践主要是在于使用Docker来进行环境的配置和使用。
image(镜像)和container(容器)的关系
镜像(Image):Docker镜像是一个静态文件,其中包含了应用程序运行所需的所有文件系统内容、库和配置。镜像是一个只读的模板。它可以用来创建一个或多个容器。
可以简单理解镜像是一个制作好就无法修改的模板
容器(Container):Docker容器是镜像的运行实例。它实际上是一个独立的、轻量级的、可执行的软件包,包含了运行应用程序所需的一切:代码、运行时、库、环境变量和配置文件。容器可以被创建、启动、停止、删除和移动。每个容器都是相互隔离的,具有自己的文件系统、网络和进程空间。
容器可以看作一个镜像的动态转变,将其从静态唤醒变成一个应用,可以运行修改。
下面的状态图,阐述了使用过程中的状态改变:
graph TD;
A[Docker Image] -- 创建 --> B[Docker Container]
B -- 基于 --> A
B -- 运行 --> C{应用运行中?}
C -- 是 --> D{正常}
C -- 否 --> E{已停止}
E -- 重启 --> C
E -- 删除 --> F[Destroyed Container]
D -- 删除 --> F
简单理解了容器和镜像的关系,我们可以尝试安装Docker并在Docker部署一个应用,这个应用可以是很多种类型,比如:部署一个可以使用显卡的运行环境(依赖环境也是一种应用)。
Docker本身的安装
这里不再赘述,可以参考另一篇维护的文章,当中Docker部署的部分。
通过portainer构建自己的容器
portainer部署在No1服务器上,portainer是用来管理所有Docker的管理软件,同时也部署在Docker之上,使用portainer来创建容器的目的是减少命令的输入,方便用户使用,降低Docker的使用门槛,图形化的管理界面也比较直观的展现了所有容器的信息,减少创建过程的问题,同时Portainer具有服务器集群管理,节点拓展等功能,为以后实验室服务建设添砖加瓦。
首先登录你的Portainer
每个人的账户已经创建好了,需要登陆密码私聊我即可。
目前被部署在:https://10.26.58.61:9443/
使用zerotier的时候地址为:https://10.11.12.166:9443/
注意端口号为9443
登录页面如图:
登录之后进入到管理界面:
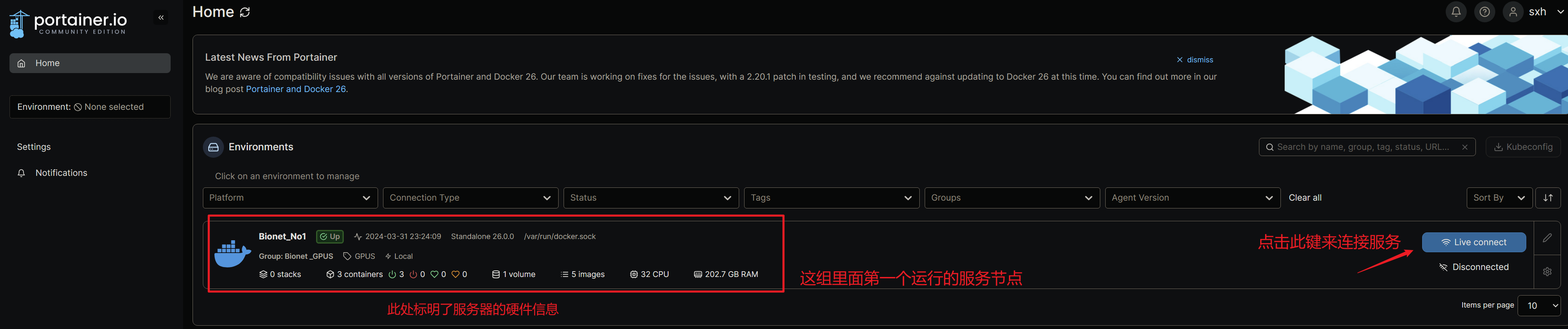
点击链接按钮之后,下图就是其管理界面:
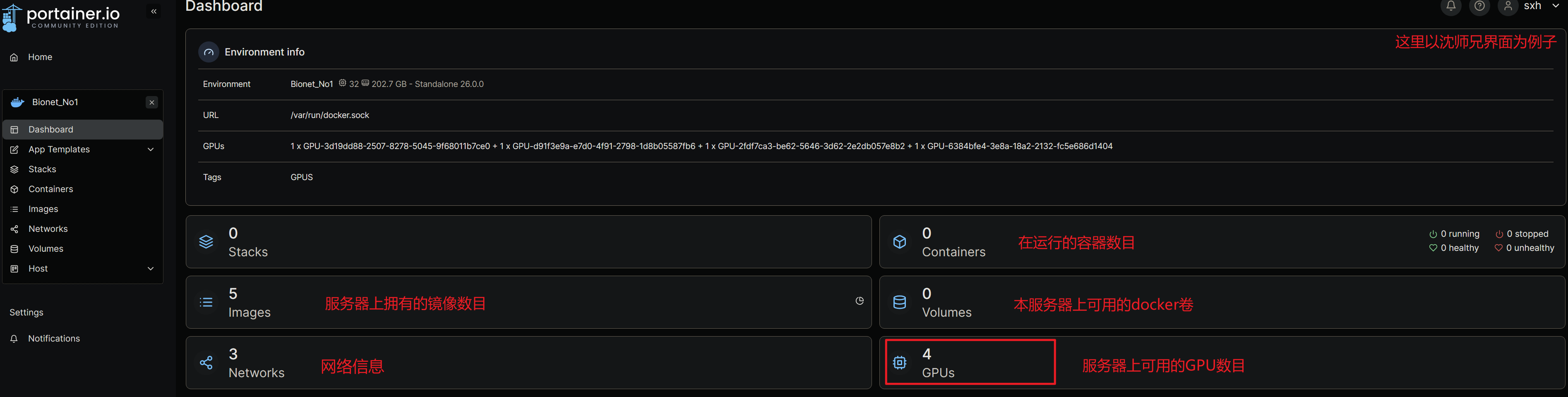
不过这里不是我们的主要目的,我们将目标放到右侧选项栏之中:
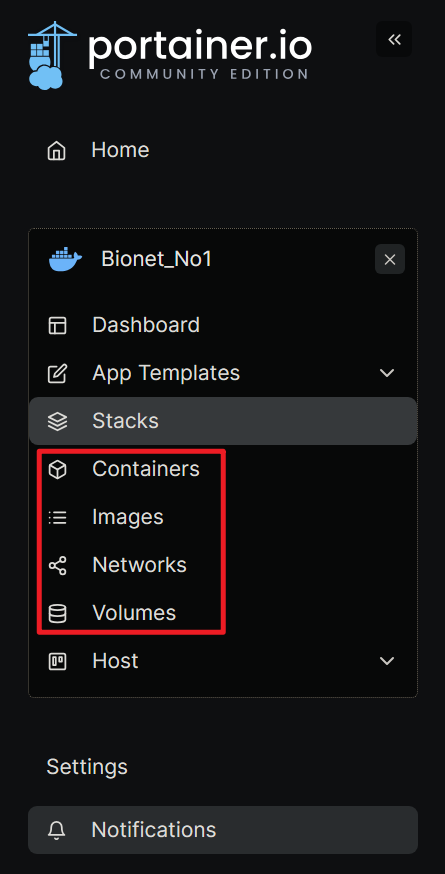
对于使用者来说,右侧的状态栏我们只关心这四个内容,Containers、Images、Networks、Volumes,下边将简单介绍一下这四个内容并在介绍的同时创建一个属于你自己的世界(容器)。
Images(镜像)
我们先来看一下Images页面,Images中文名称就是镜像,镜像在制作完之后和使用之前是无法更改的,也就是说镜像实际上就是某一套环境的固化版本、无法修改当中的内容,只能使用当中的内容。
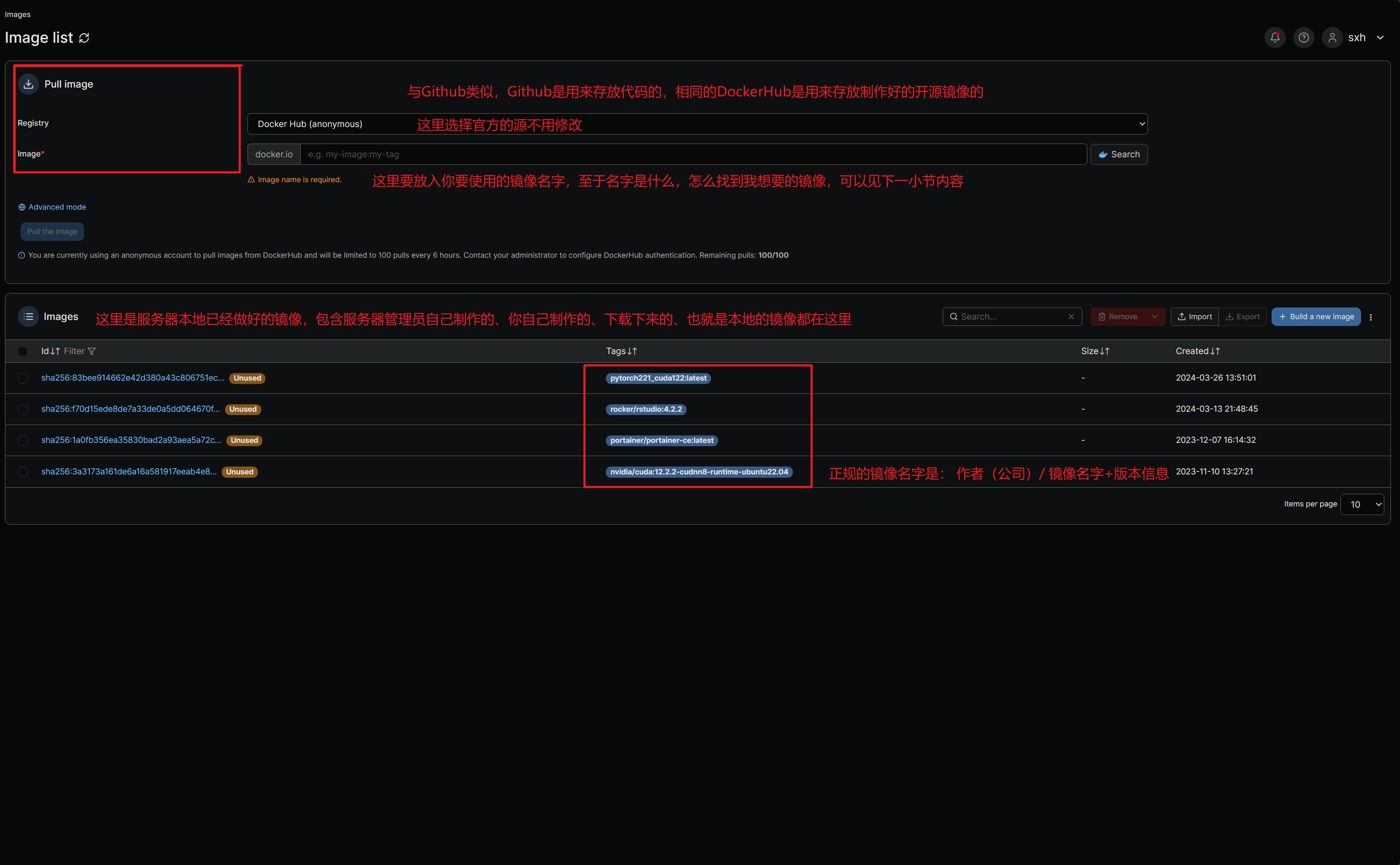
可以看到我们有一个不太正规命名的pytorch镜像,这是我第一次制作的镜像,我们可以通过一个基本的镜像来详细介绍一下镜像如何使用和创建,我们使用这里最后一个镜像来在nvidia的cudnn运行环境来进行测试。
container(容器)
容器就是镜像运行起来的状态,这时候镜像内容就由上文中不可修改的状态转变为可修改、可运行、可探查的状态,一个镜像包含了一套完整的运行所需依赖,并由一套自己的文件系统来支持运行,也就说容器和本地服务器是隔离开的、是互相不干扰的,是没有任何关系的(其实并不是,也有一定的逃逸方法,建议大家正常使用就不会遇到这些问题)。
以下为从零开始创建一个新容器,本文也有直接从一个已有容器复制新容器的使用指南,但是更推荐看完从零开始创建容器并自己动手跟着操作一遍,遇到问题可以随时联系管理人员。
来到container页面:

可以看到没有任何东西,这样我们就需要创建一个container,点右边的按钮来创建:

上图中演示的是NVIDIA的官方镜像,我这里也制作了几个适合组内任务的镜像,简单介绍下镜像列表如下,请选用neonexus开头的:

这里以neonexusx/bionet_deeplearning:cuda121_cudnn9_conda_pytorch_devel_v1.1这个镜像为例,说明一下名字的含义
neonexusx/bionet代表是Docker hub的仓库所属者,deeplearning代表镜像用途(深度学习),后面的cuda121代表cuda 12.1版本,cudnn9同理,conda代表存在conda虚拟环境,pytorch代表深度学习框架,v1.1是版本号(镜像不定期会更新,可以实时关注下)至于选用哪一个请自行参照上文选择。
设置主机和容器的端口号映射:

主机可使用的端口号在10086-10199之间,每个人使用的数量不受限制,只需要选择没有占用的即可,这里我占用的是10086,所以别人也无法使用了,但是如何查看别人用了什么端口号呢,使用相同的端口号会导致创建失败。
容器需要使用的端口完全取决你的应用需要,比如R Studio就需要8787端口就需要将R的端口(8787)映射到10086到10199之间任意一个,当你从你的电脑链接的时候只需要选择你当时映射的主机端口号即可,不需要连接的时候选择8787。
这里我建议你多留一个端口比如容器的10087来映射到10087来使用,这样万一有服务需要使用端口我们只需要重新映射一下服务即可,就不要再重新创建一个端口来使用了。

容器的配置
最下面就是容器的详细配置了:
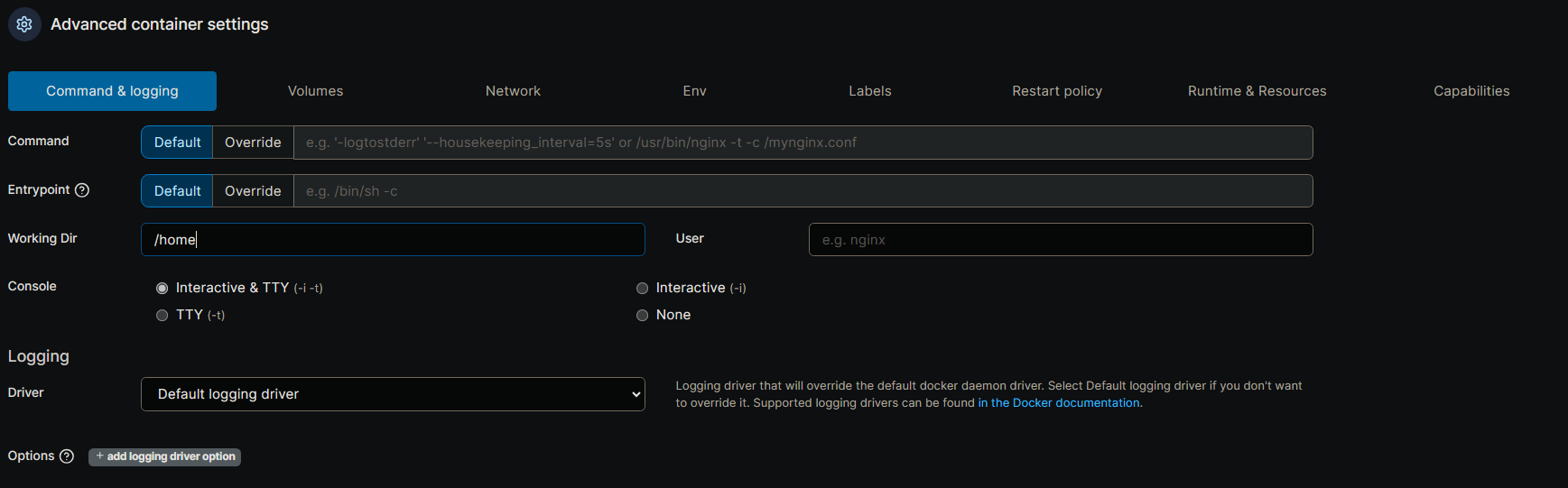
关于容器的配置这一部分,需要说明的是,大多数容器的配置都是一致的,只需要修改名字即可,填写请按照我给出的内容来填写,第一部分需要配置的比较少,按照图上的内容配置即可。
存储配置
不要照着下面这张图片直接抄,请先看后边的内容:
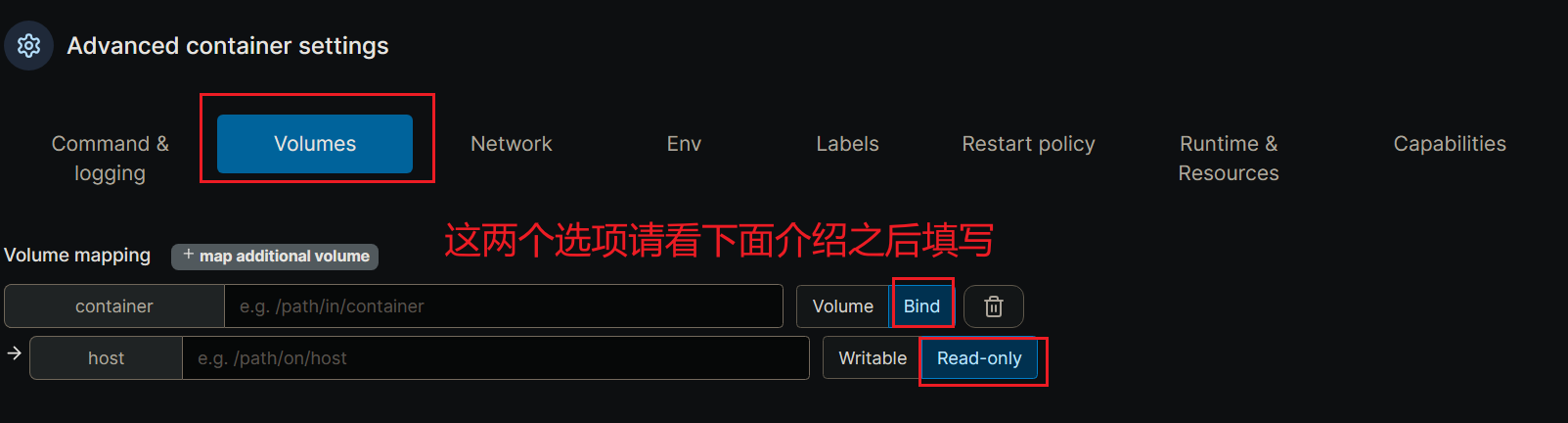
Bind类型不要选错!
bind是绑定本机路径到容器上某个路径之下,实现对应路径的内容在主机和容器之间相互共享的方法。
举个例子:
type=bind, source=/home/SoftWares/R_Share , target=/home/R_Share,readonly \指的是将主机:/home/SoftWares/P_Share目录内容绑定到容器的/home/R_Share路径,注意这里的sorce指的是你的服务器本机端、target指的是容器端。
这样这部分就可以互相共享文件,readonly指的是权限为可读,这样的设置当然是为防止你使用某一个数据集的时候有别人来篡改数据,造成你完全无法知晓跑出来的结果。
同时因为容器是以root权限来运行的,如果不使用readonly来限制很有可能你一条rm命令将大家的数据都删除了,这将造成无法挽回的后果。
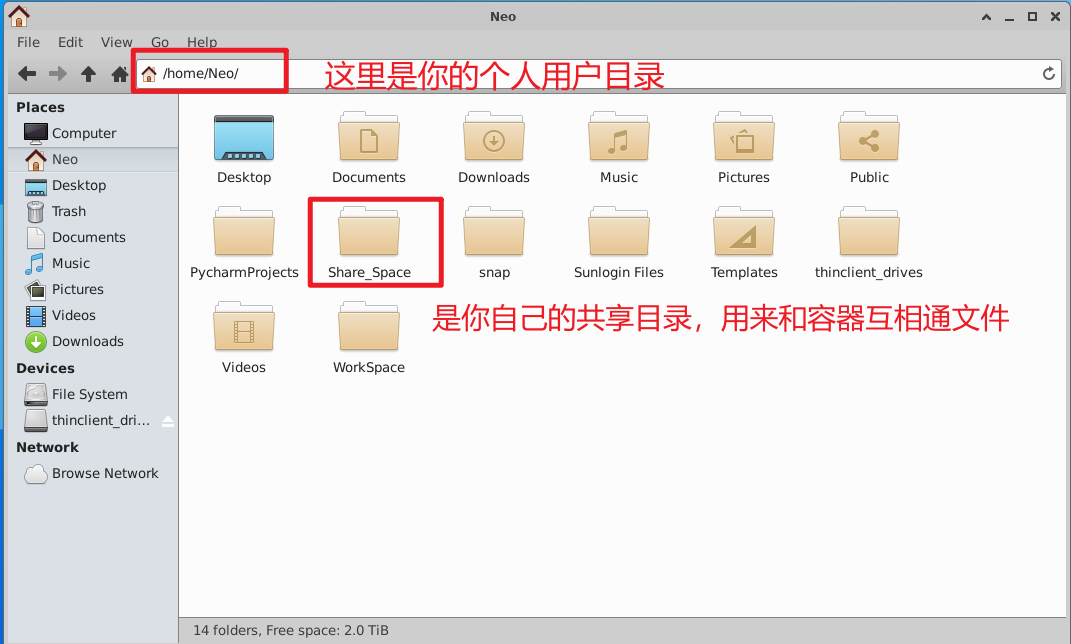
type=bind, source=修改这里/Share_Space, target=/container/path/Share_Space \
Share_Space目录就没有只读权限这样的担忧,因为这个主机端的文件夹只有你能访问,这个文件需要你修改修改这里这四个字改成你的个人home目录:'/home/Neo/Share_Space '举个例子:
存储配置的最佳实践
下图展示了存储配置的最佳实践,需要结合NAS使用指南和当前讲解来理解:
graph LR;
A["容器(最高权限)"]
B["服务器主机A"]
F["服务器主机B(待建设)"]
C["NAS(网络附加存储)"]
D["你的本地电脑"]
E["外部网盘"]
A--"Datasets文件夹依赖于"--->C
A--"运行依赖于"--->B
A--"运行依赖于"--->F
B--"Datasets文件夹依赖于"--->C
F--"Datasets文件夹依赖于"--->C
A--"NCZone、R_Share、P_Share文件夹直接存在于"--->B
D =="Bionet(Datasets)文件夹依赖于"==>C
D--"连接运行"--->A
E--"数据"-->D
红色的路径为推荐的上传数据集的方式:详见NAS使用说明。

当你明白上述目录之后我们来填写上图中的内容,我已经简单写了一份出来,你只要复制其中的路径即可,不要搞错了主机和容器的区别。
host=/home/Datasets container= /home/Datasets, readonly
host=/home/Neo/Share_Space container= /home/Share_Space Writable
注意这里的host指的是你的服务器本机端、container指的是容器端,其他的内容按照图片选择即可。

使用Tensorflow的同学注意需要将上图container的home替换为tf,如下图所示:
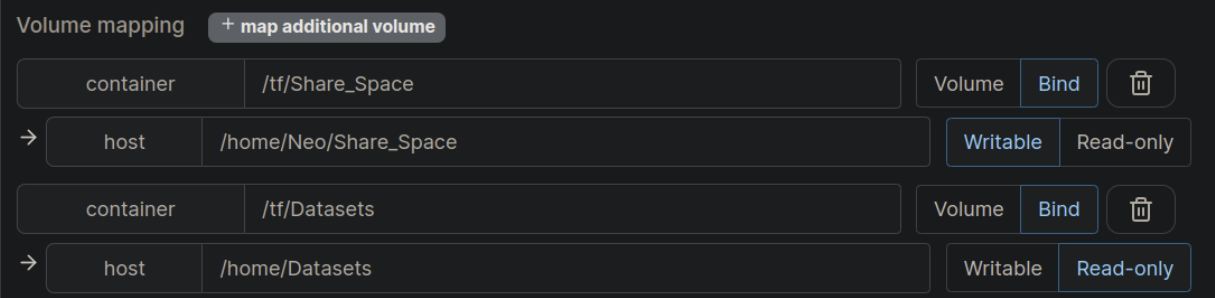
lable配置

重启策略配置

运行时配置
将页面切换到此处:

shnm大小推荐至少128000MB,最大256000MB,使用多卡或者datakloader数量较多的程序请在16000MB以上。
此处注意,因为有两组成员共用GPU,请bionet课题组使用如下配置:
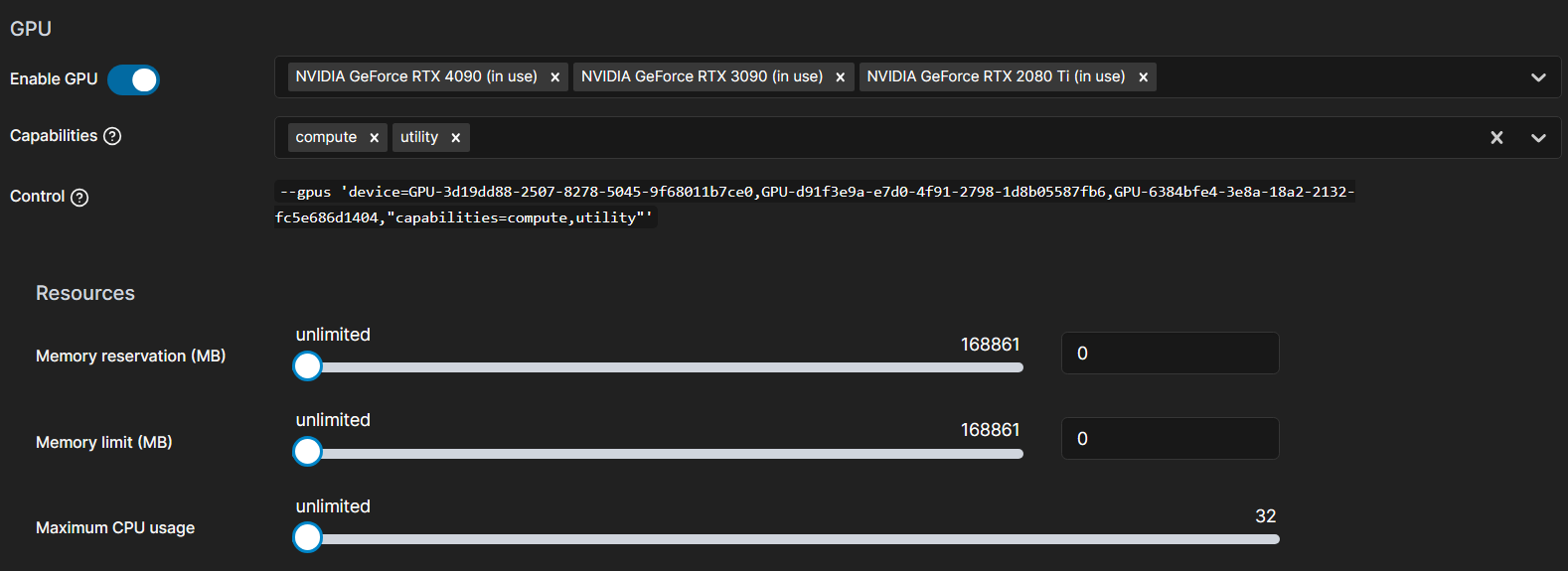
另外的成员,请使用如下配置:

最后一定要点击部署!容器才会生效~这个按钮就在基础部分。

创建完成之后我们就来到这个页面,可以看到容器已经在运行了:

我们点击这里按道理是可以进入命令行的:


同时这里也有容器的监控信息:

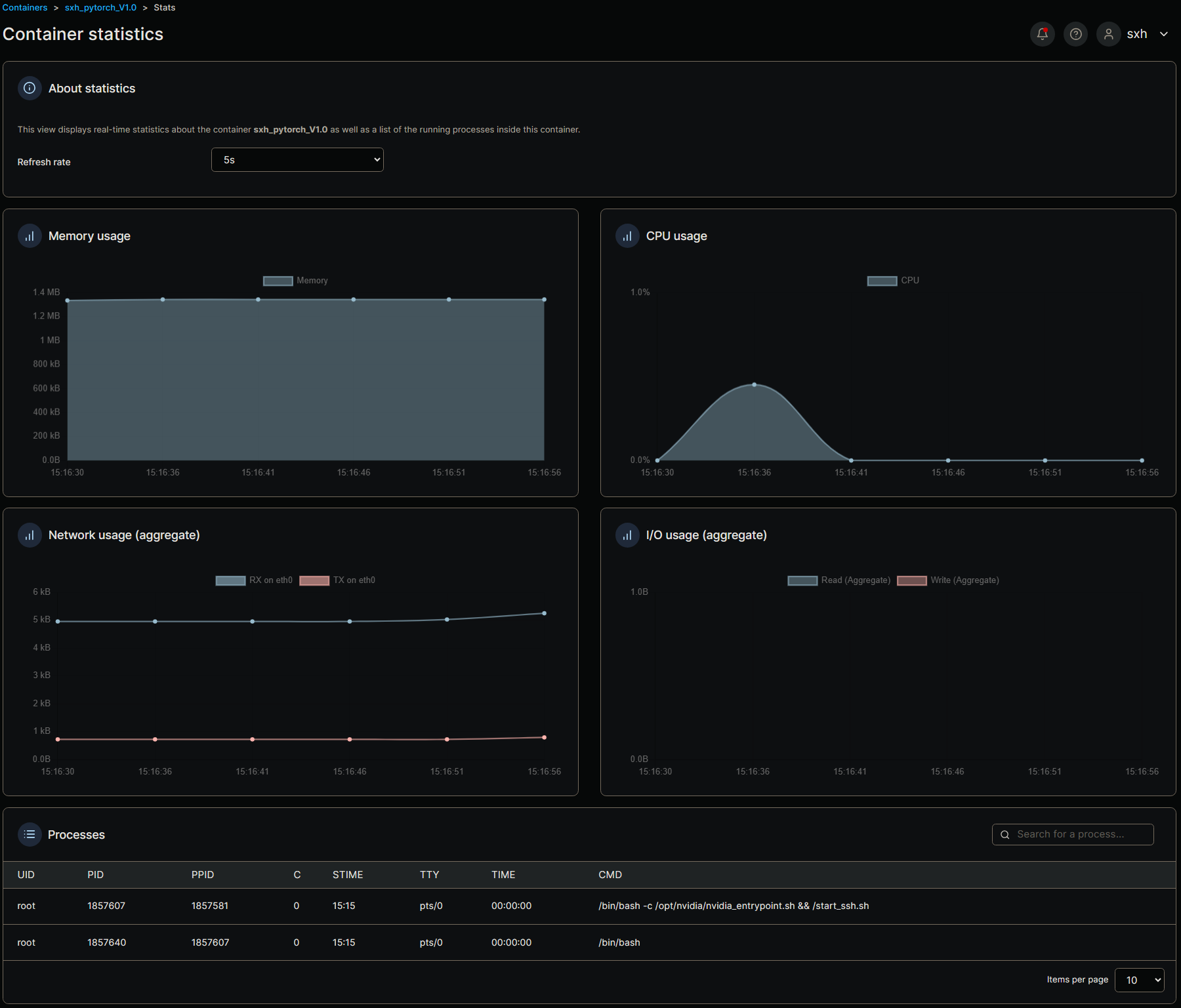
Tensorflow使用Jupyter登录
Tensorflow环境使用Jupyter来使用,在上述镜像建立完成之后,我们首先找到我们映射的端口信息

点击镜像名字查看端口信息:
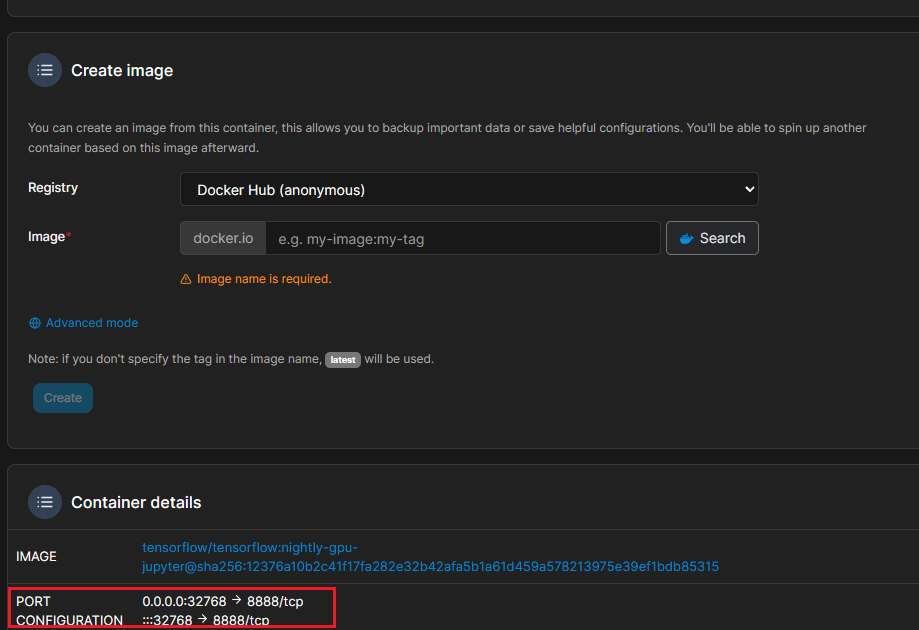
我们这里使用了32768端口来映射Jupyter的8888端口,我们打开浏览器输入:10.26.58.61:32768
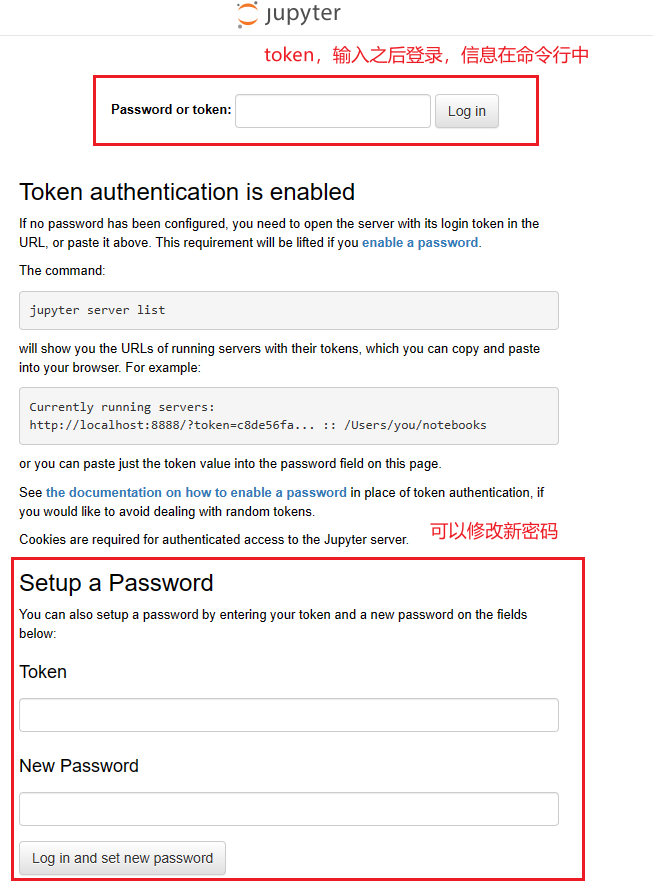
建议第一次就设置好密码,输入密码,这样每次就不用单独去查找API_token了
接下来我们去命令行找到token:

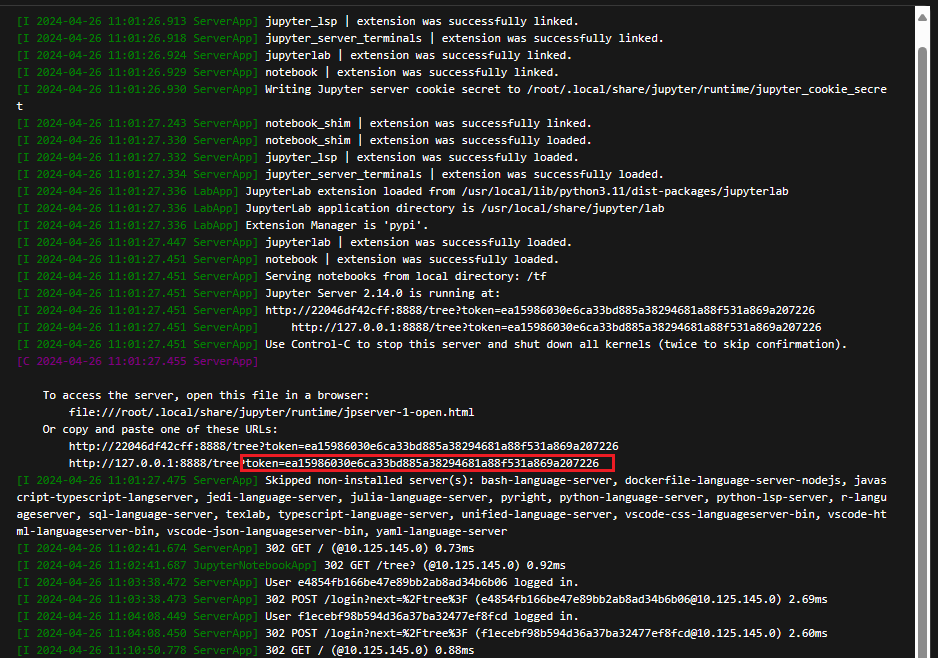
复制对应的token即可使用,也可以选择下边的修改密码来长久登录。Jupyter自带命令行,所以Portainer的界面的命令行无法使用们这里需要注意。
关于Jupyter的使用这里就不再赘述,下面是pytorch的vscode链接方法。
使用已有容器复制
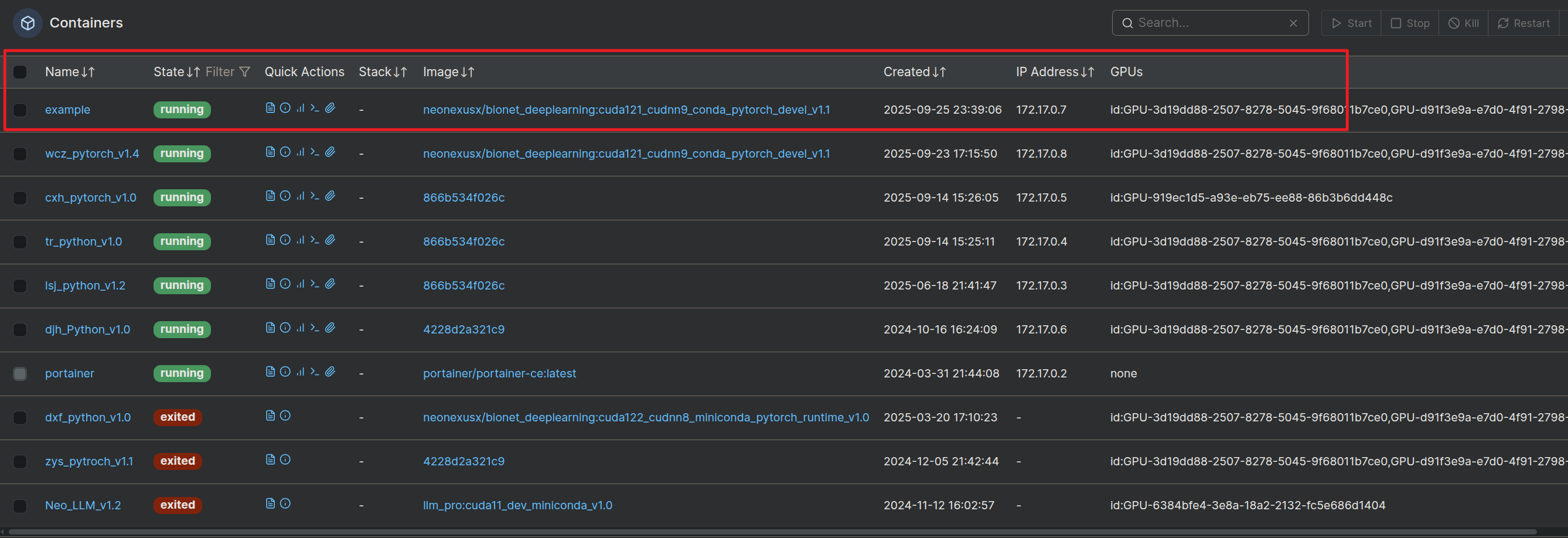
如图所示,example 是按照上面流程创建的标准容器,通过对标准容器的修改可以可以直接使用别人生成好的容器配置,但需要注意的要修改端口,绑定硬盘路径等参数就可以生成符合你的使用需求的一个新容器。具体操作步骤如下,先点击你想要复制的容器(以example为例,下同)
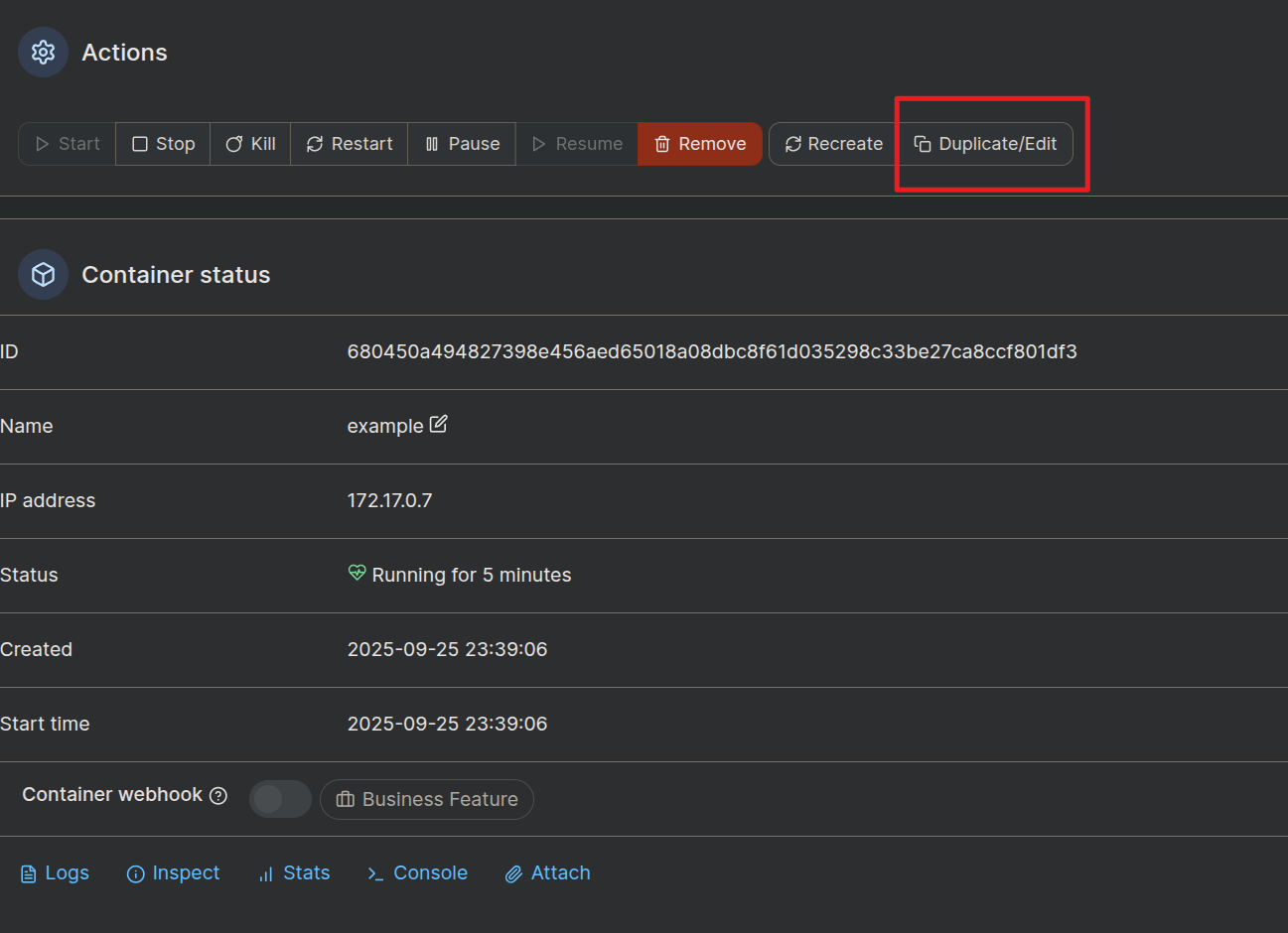
点击Duplicate/Edit,进入如下界面
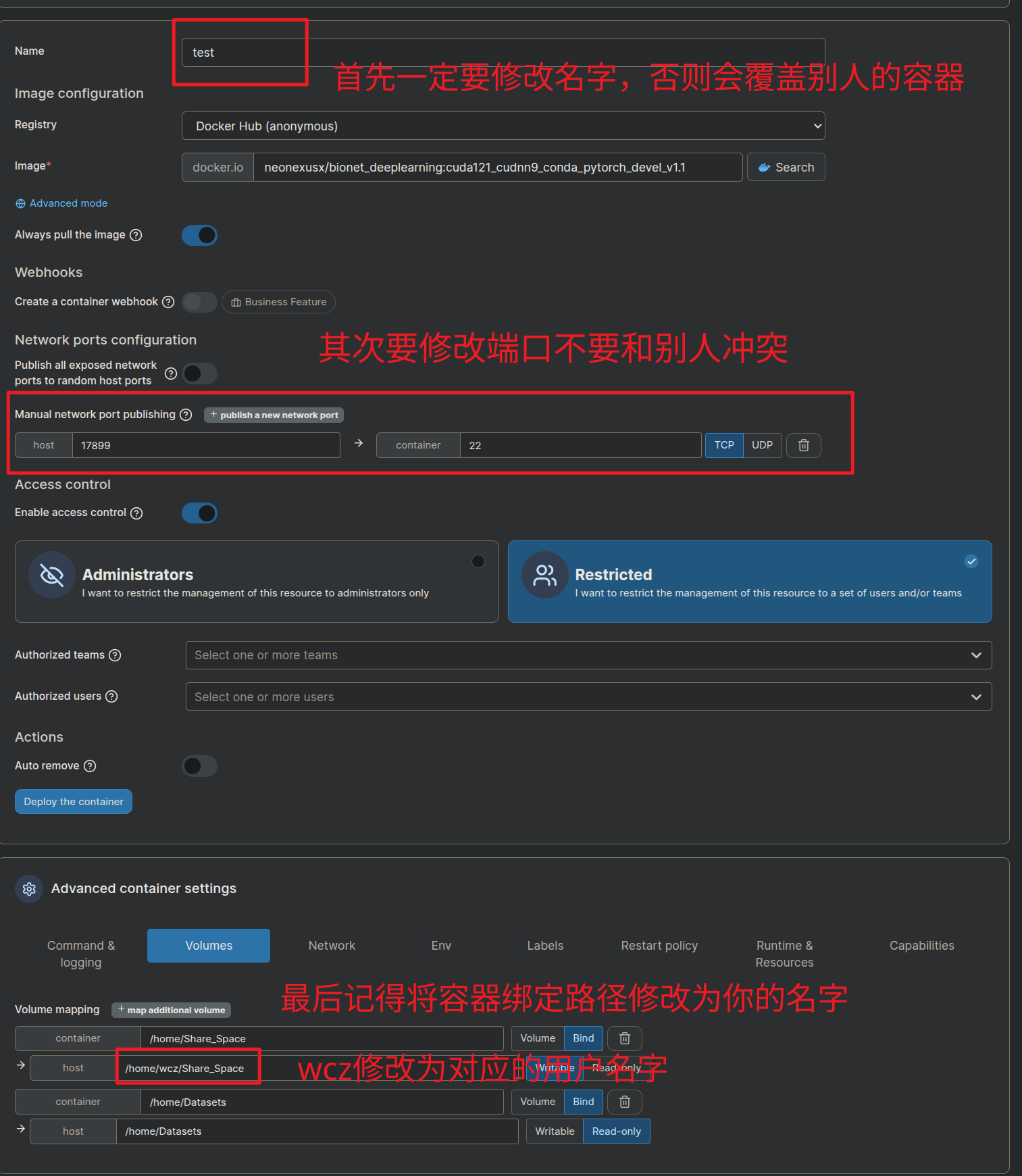
记得点击
来保存容器
之后就会得到一个新的容器了
复制容器的好处是简单快捷,可以根据自己的使用场景微调镜像,但是还是推荐大家去看上面的从零开始创建容器的部分,可以深入的了解每个选项的作用,有问题也可以自己简单修复下。
使用VSCode连接容器
下载vscode:Visual Studio Code - Code Editing. Redefined。推荐使用新版。
在连接之前我们先来使用Portainer来重启一下SSH服务,优化conda内容,方便来链接:
我们使用Portainer自带的命令行:
点击这里打开容器的命令行。输入以下命令:
service ssh restart && conda init && passwd && mkdir ~/.ssh && touch ~/.ssh/authorized_keys && chmod 700 ~/.ssh && chmod 600 ~/.ssh/authorized_keys
命令行中粘贴快捷键为ctrl+shift+v,这里减一直接复制以后粘贴。
命令的效果是修改密码,并增加一些系统设置内容。
效果如下所示:
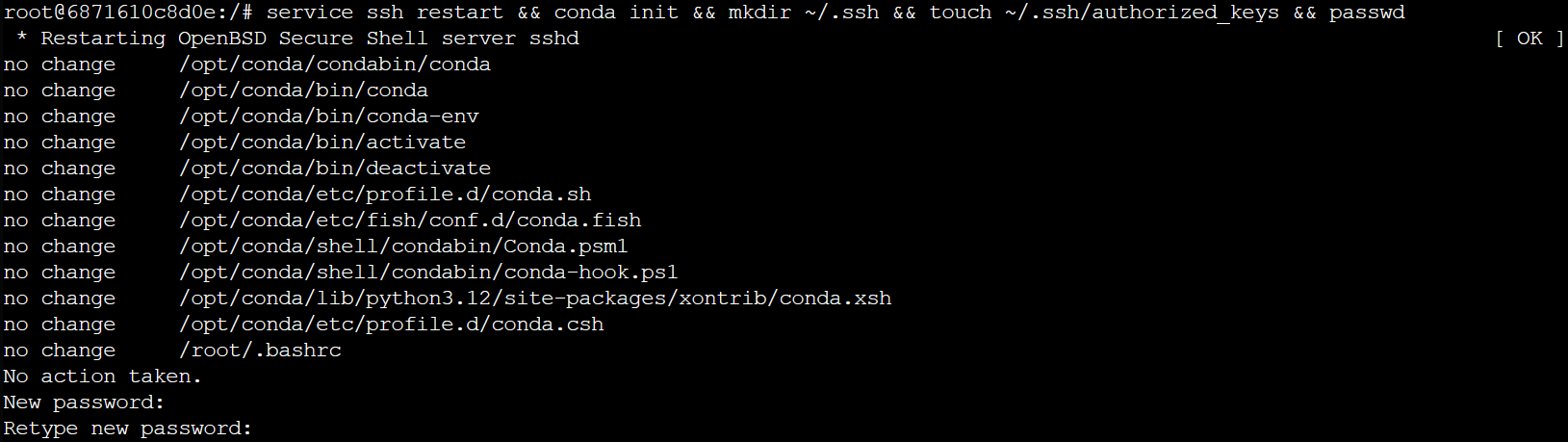
注意这里修改密码要输入两次才可以,如果有一次和上一次输入的不一致就会失败,如下图所示:

**不用紧张,再次输入上一个命令即可。**然后关闭这个页面。
使用最新版的VSCode,这里下载安装就不再赘述了,打开Vscode之后:
新版的vscoe自带remote链接如图所示:
如果没有的话,请去插件市场安装一个:
选择左侧Extensions选项卡,在输入框搜索ssh,选择安装Remote-SSH插件。这里我已经安装。
安装之后让我们打开远程连接:
可以看到有两种链接形式的存在:一个是tunnels另一个是SSH,这里选择SSH,点击加号创建新的连接:

点击之后会让你输入命令:
端口号要更改~
ssh root@10.26.58.61 -p 10086
这里的-p指代的是端口号,也就是上文中所设置的端口号映射号,SSH服务默认使用22端口号我们将容器的22端口映射到服务器本机的10086端口,所以这里就要使用10086端口作为链接方式,这样我们只需要连接10086端口就可以连接到容器,注意这里的端口号要和你的容器设置保持一致。
这里一定要修改成你的端口!!!!!!!!!!!!!!!!
你可能会好奇为什么会是root,而不是其他用户,这里使用的root命令,是因为容器里面的root和主机的root并不一致,这里的root是容器中的管理权限用户,和外边并不相关。
在你的容器里面你就是root!
然后按下回车:
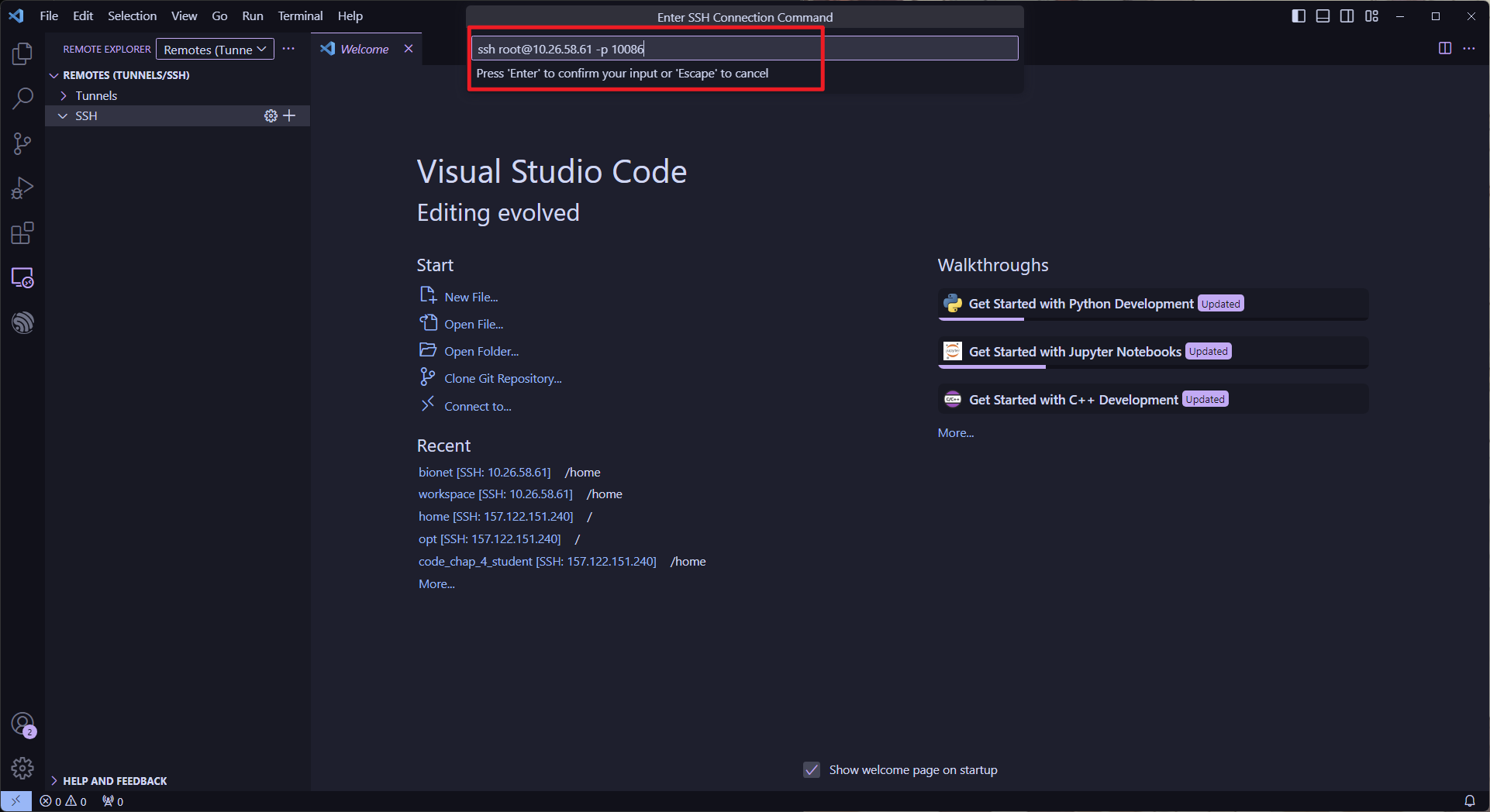
一定要记住这个路径,万一有错误可以用到。
然后右下角会弹出链接提示,选择链接:
没有看到没有选择上也没关系,我们刷新一下列表就能看到链接信息了:
点击链接,输入密码之后开始下载,就说明成功了,容器的root密码为通用的123456:

一般工作在home文件夹下:
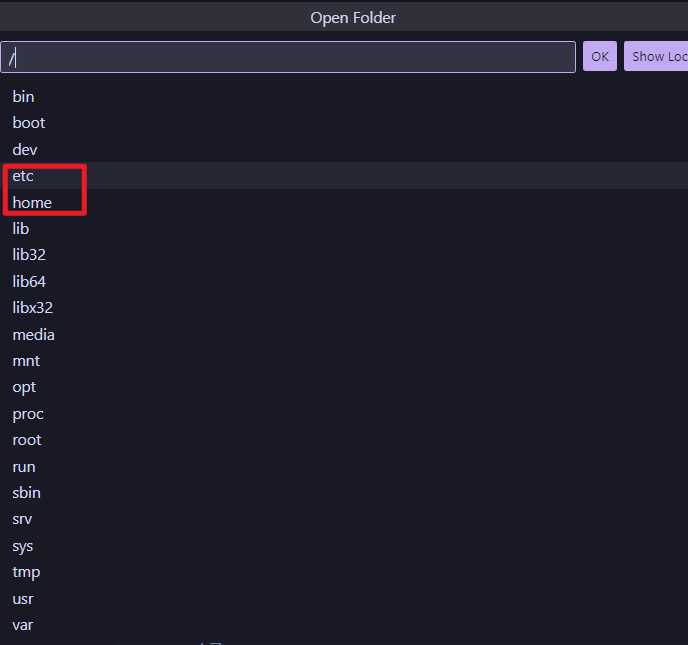
可以看到刚才挂载的几个位置:
我们在这里新建一个python脚本来测试:
将以下内容插入:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def main():
cudnn.benchmark = True
torch.manual_seed(1)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print("Using device: {}".format(device))
kwargs = {'num_workers': 1, 'pin_memory': True}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, epoch)
if __name__ == '__main__':
main()
新建之后会有右下角来提示安装对应的语言插件:
没提示直接搜索也可以,在插件市场搜索:
@id:ms-python.python
同时还需要pylance,作为语法检查。
然后点击安装在远程即可。
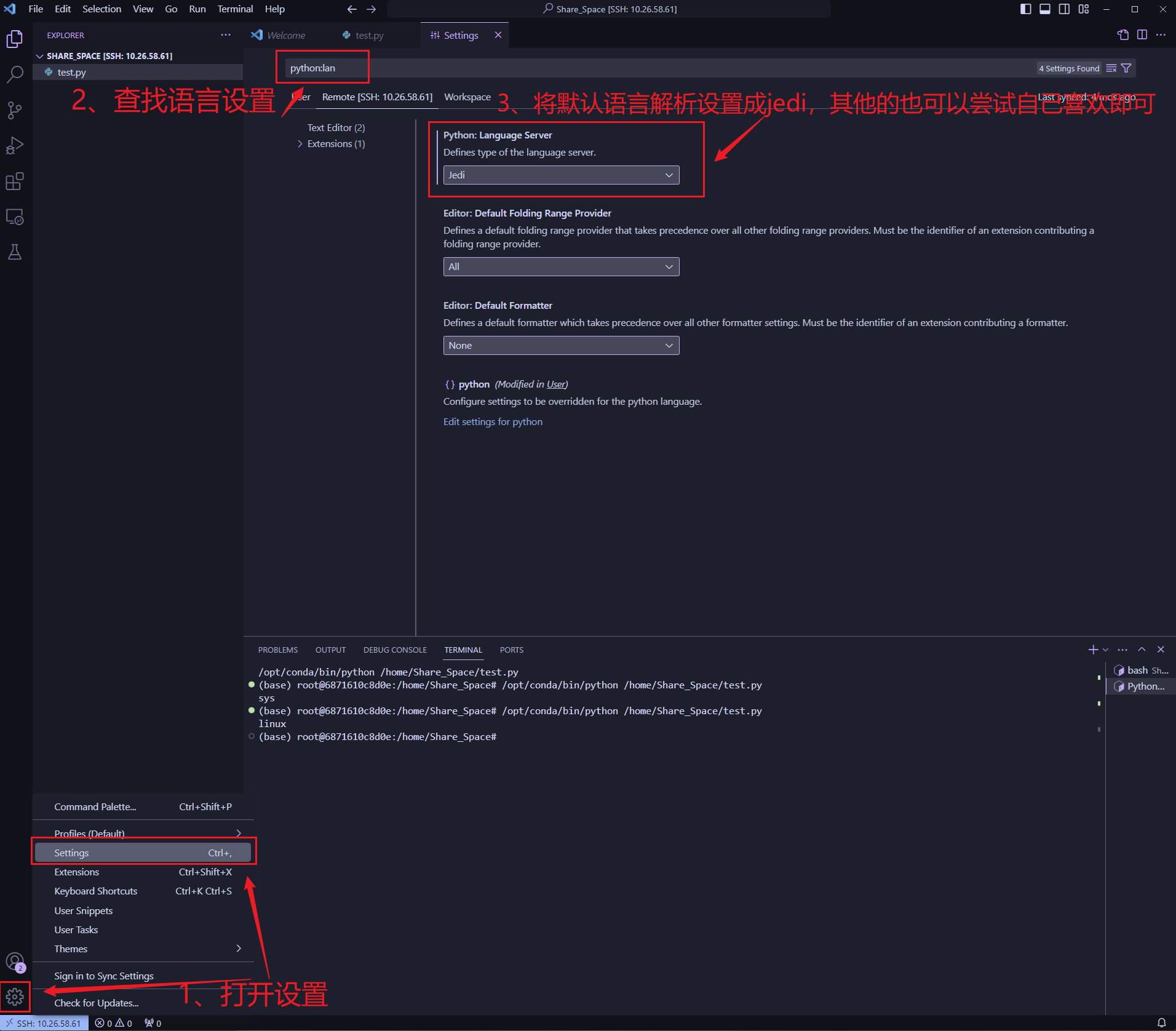
开启代码补全
由于默认的代码补全并不是很好用这里要修改一下设置:
同时打开terminal来测试:
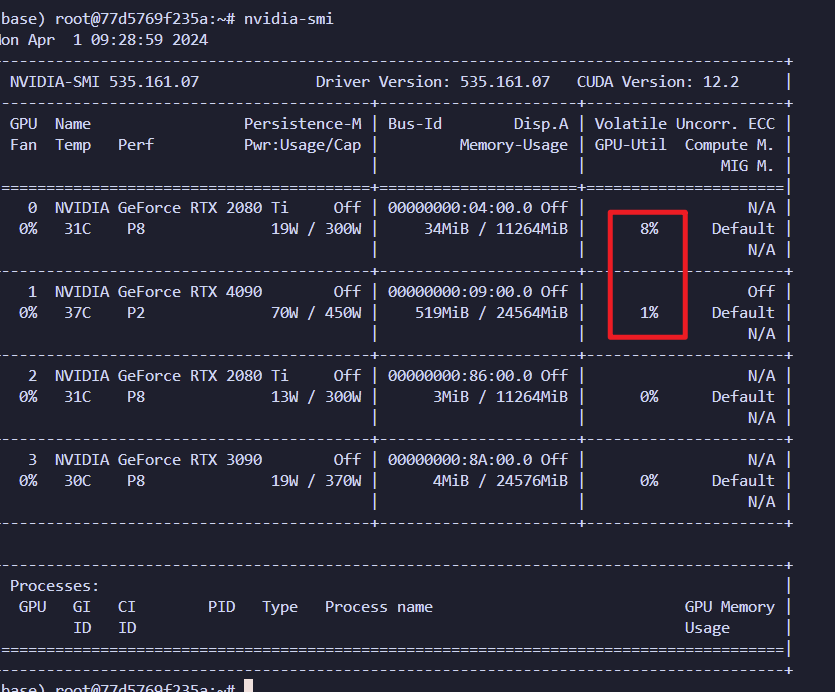
输入命令:nvidia-smi
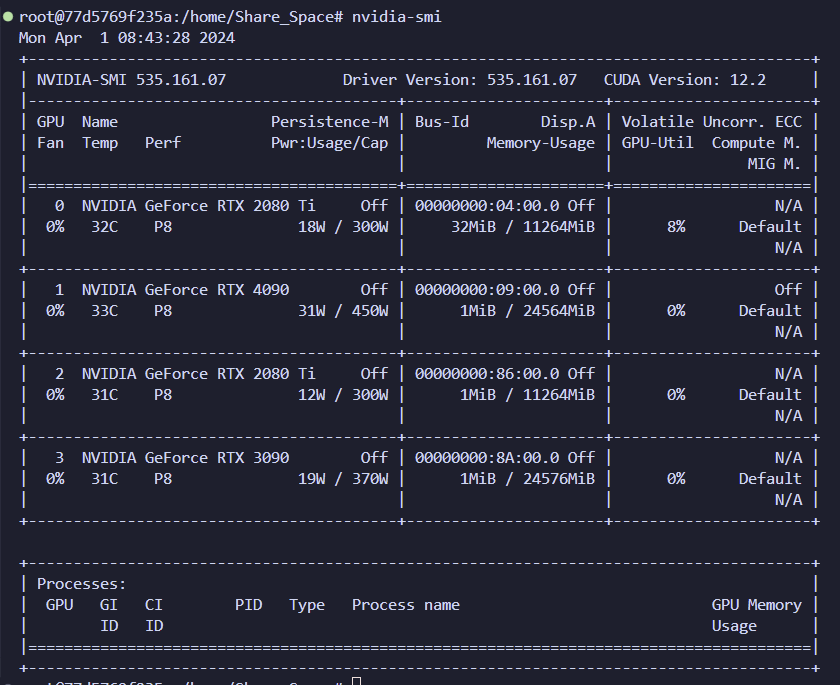
如图所示,四个显卡都能看见,则创建成功。
使用conda来创建环境,初始化codna:
conda init
重新开一个terminal:
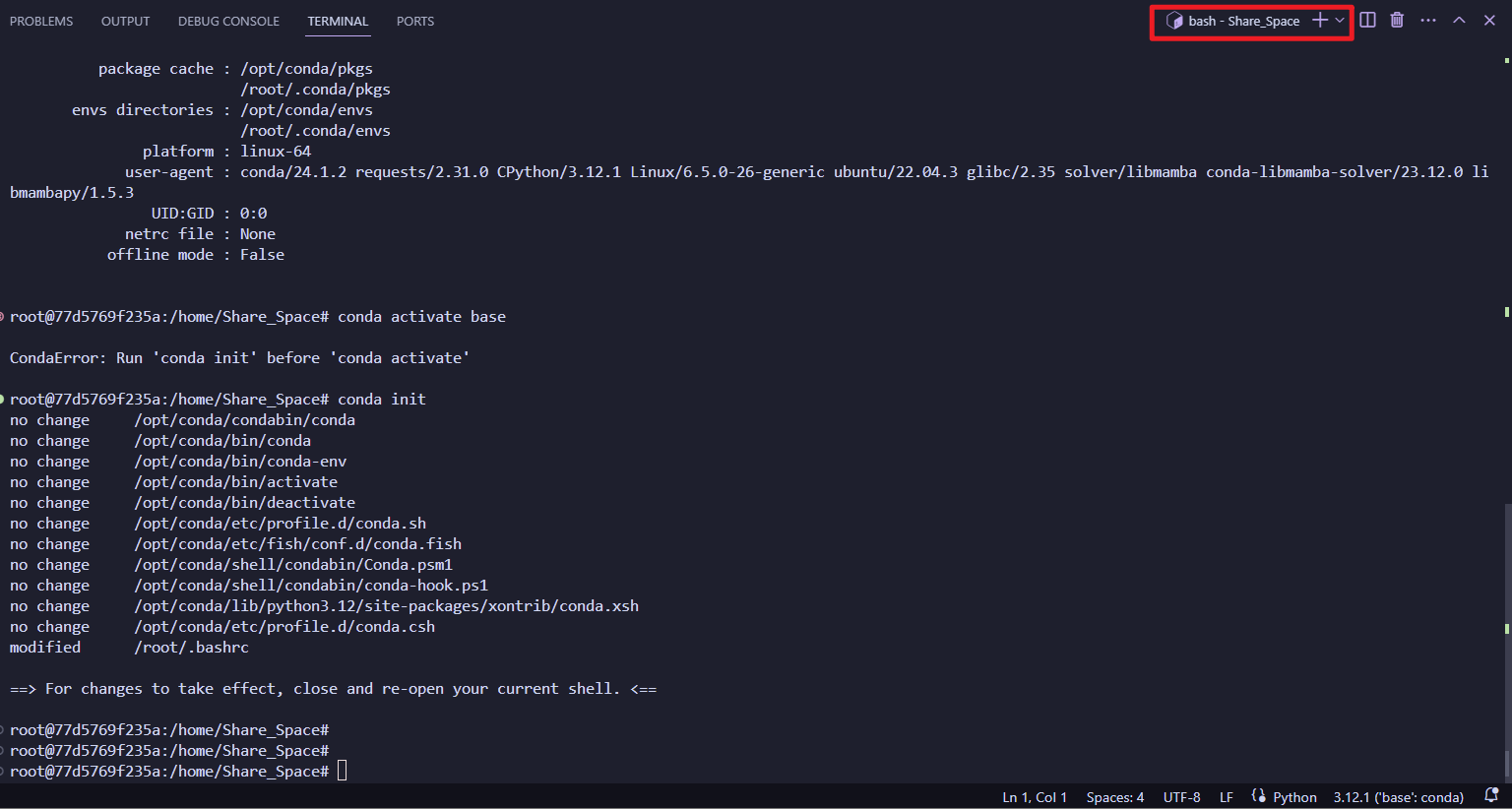
可以看到cnoda已经成功启动了:

在安装之前我们来进行换源,我们将目录切换到这里:
新建一个:
复制以下内容进去,记得ctrl+s保存:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
deepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/
最近清华源也不太稳定~,使用后无法下载删除文件恢复默认即可:
使用如下命令清除缓存(想要恢复默认也需要使用这个)
conda clean -i
然后,打开一个新的terminal ,看一下conda是否有更新:
使用命令:conda info
结果应是如下:
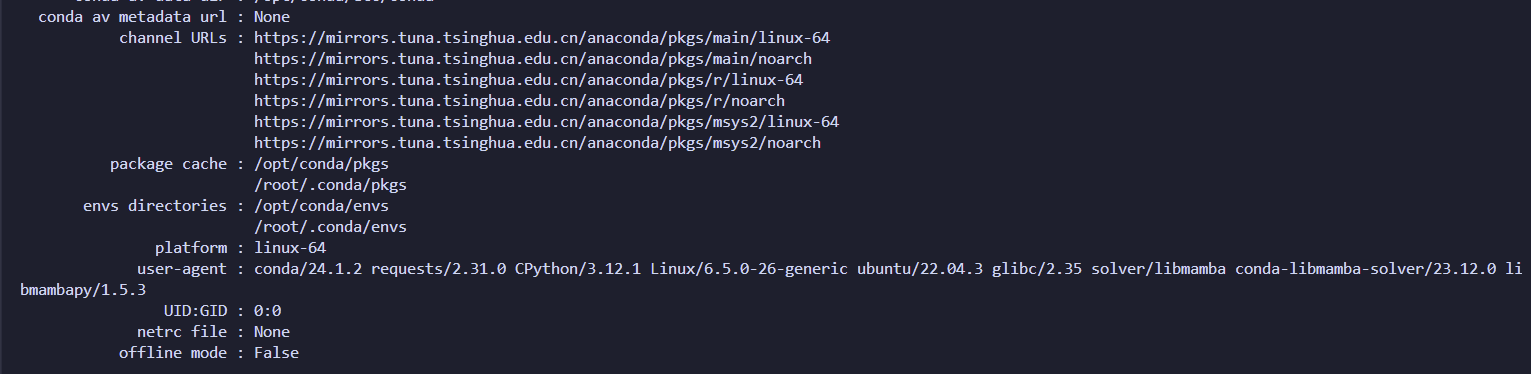
我们安装一个pytorch来试一试:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia

点击运行:
这里注意,你的当前目录不一定是你的文件夹,在运行之前要搞明白下方的命令行当前的目录在哪里是不是你想要的位置,因为在python中有很多相对路径要去处理,关于这点我们继续看下一张图:
这里我们使用ls命令:

这里MINIST数据集下载到当前文件夹下:

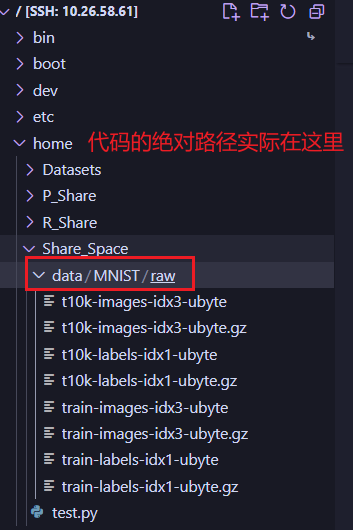
那么相对路径是./此时的绝对路径是什么呢?
不错就是命令行前端这一部分,我们打开目录就可以看到,数聚集被下载到了这里:
需要注意的是我们在base环境下安装的pytorch,右下角可以切换当前的解释器:
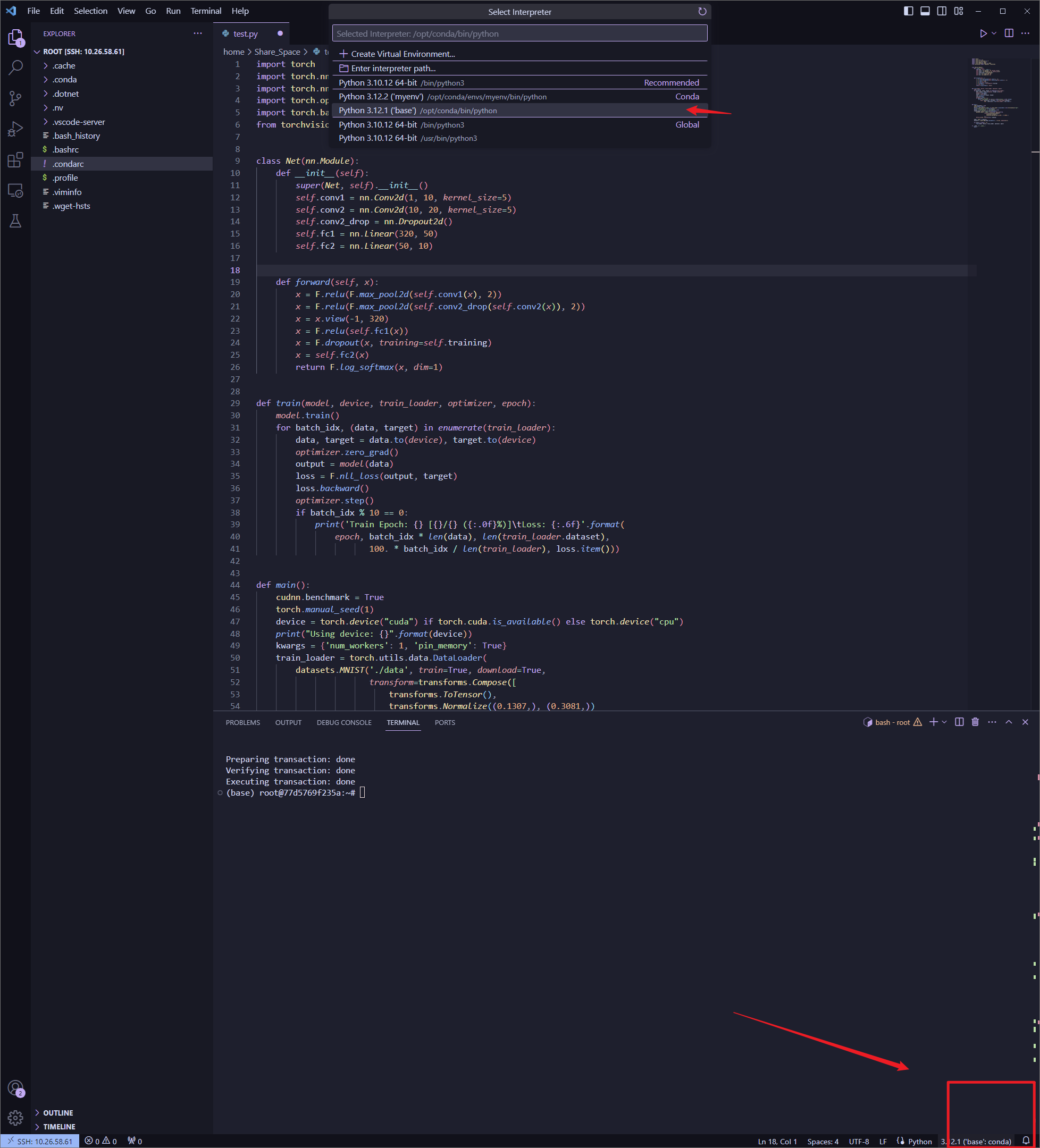
注意这里应是cuda
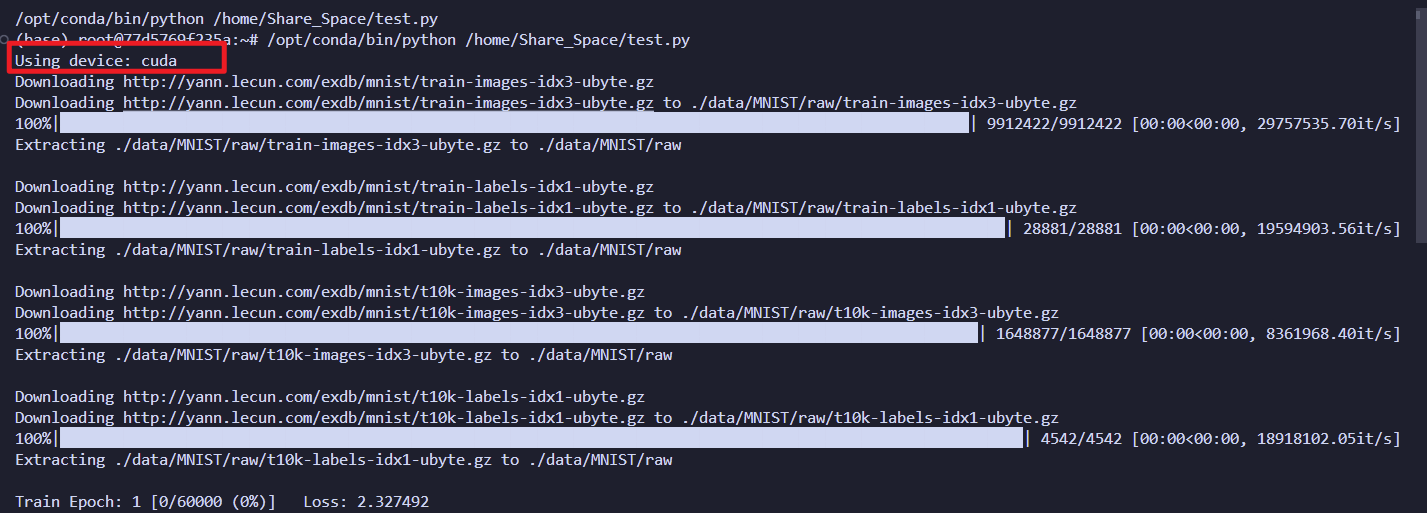
可以看到显卡被占用了:
容器的维护
维护自身的容器也非常重要,在运行的时候我们可能建立多个bash,这些bash在切换路径的时候被vscode所遗忘,就会造成内存虚高,这对我们来说是不利的,在运行代码之前,记住一定是运行代码之前,要维护好自己的容器,就少删除一些垃圾bash,使用命令:
ps -ef | grep shellIntegration-bash.sh
命令显示了多少个bash在运行:

我们保留最后一个数字最大的(因为是当前正在使用的这个,数字越大,创建的时候越靠后)
使用命令杀掉前两个:
kill -9 10970 11173
瞬间清净了~
开启免密码登录【可选】
开启免密码登录方式如下:
首先打开你的ssh配置文件:
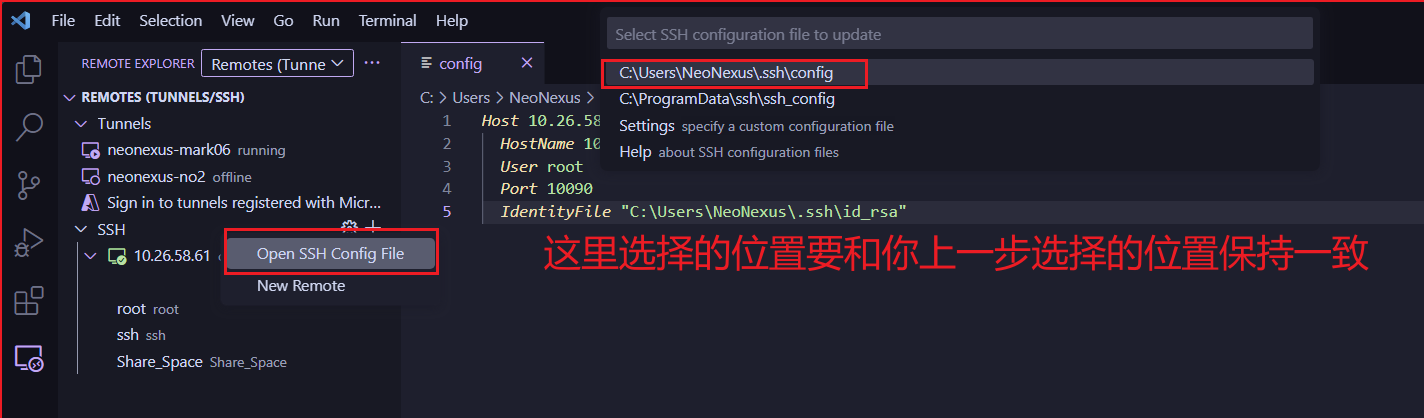
打开之后我们先放这里,等下再用。我们把这个路径叫做SSH配置路径,一定要记住这个路径,可以截图。
我们在windos文件管理器中打开这个文件夹:
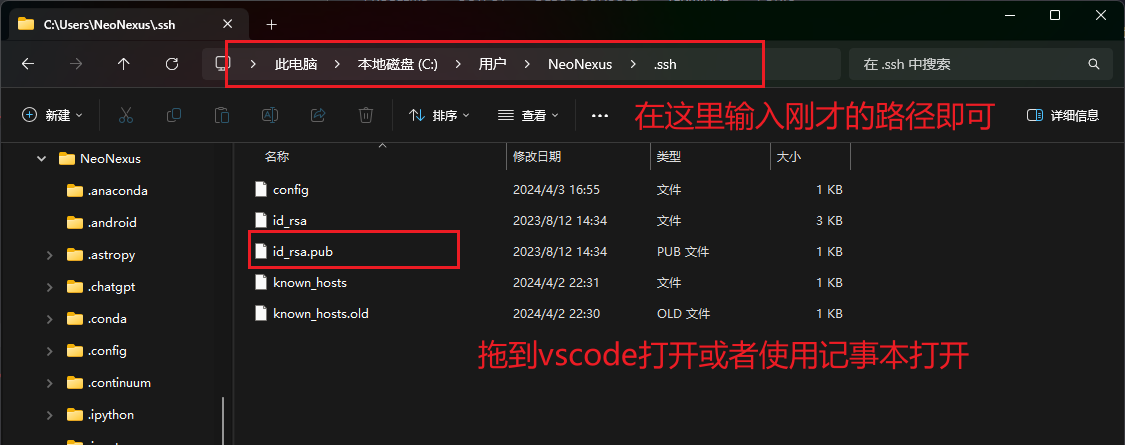
这里分为两种情况,一种是你已经有了上述id_rsa.pub文件,如上图红框所示。
另一种情况是没有这个文件,如下所示:
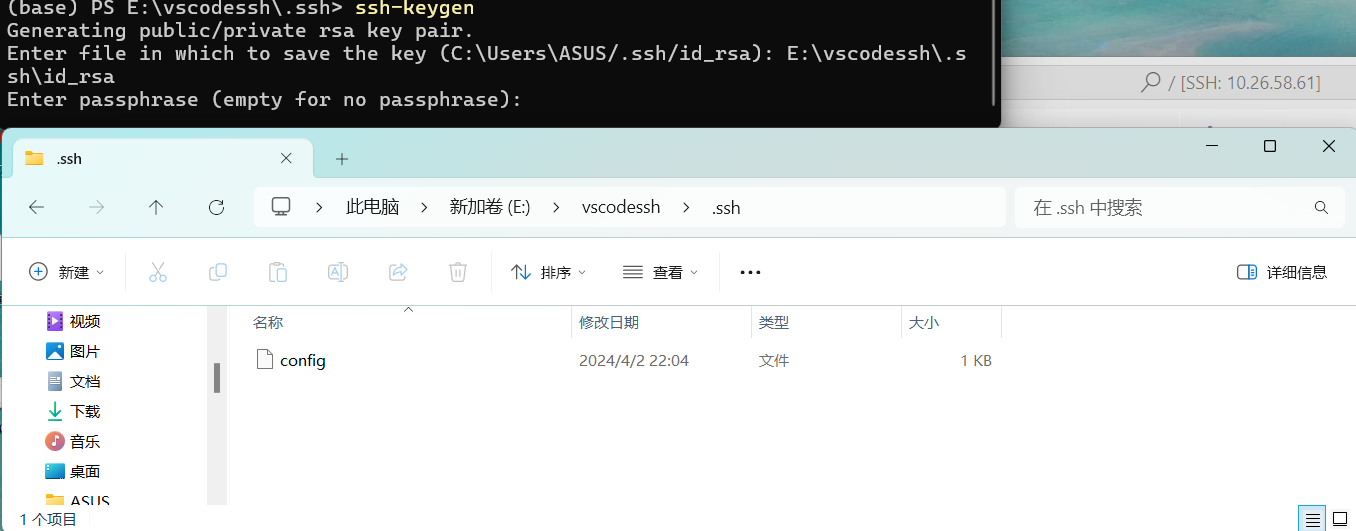
如果你没有,我们打开本地的系统命令行:
输入以下内容:
ssh-keygen

这里会提示让你输入密钥文件保存在哪里,这里就要放在你刚才的那个路径的文件下面,就是在vscode设置中打开的路径。记住是文件夹,不是文件,文件夹通常名字为:“.ssh”。
输入之后一路回车下去直到看到这个图形生成:
这里就结束了,然后我们回过头打开这个文件,使用vscode或者记事本都可以,同时我们也打开远程服务器的这个目录下的文件:
这路径全名是:
/root/.ssh/authorized_keys
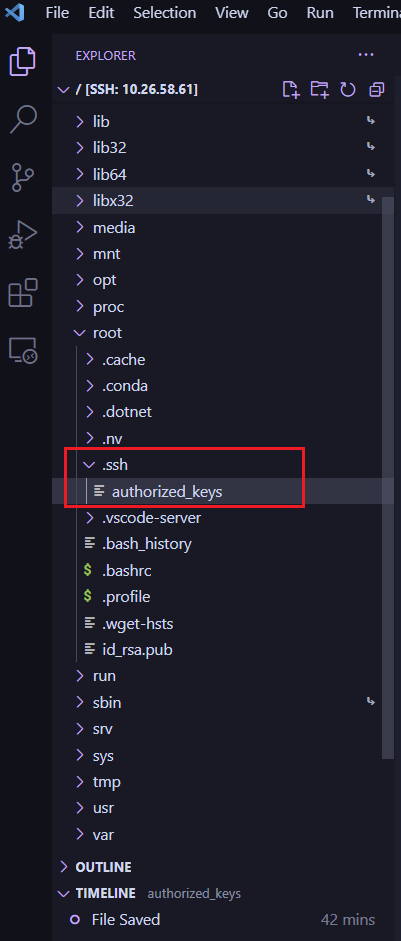
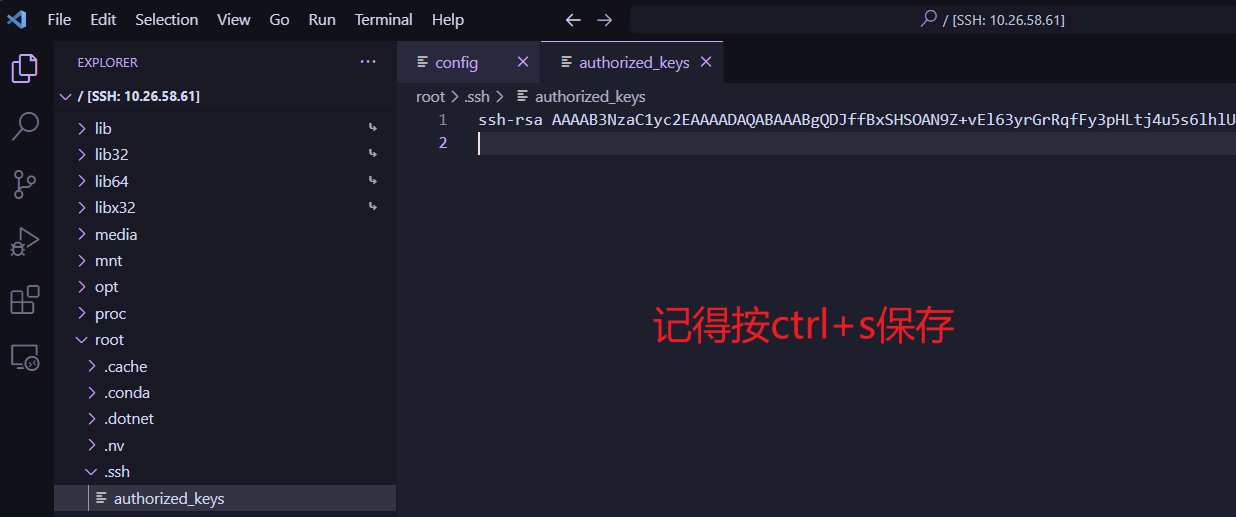
打开之后我们将刚才打开的id_rsa.pub文件中的内容复制过来,通常如下图所示:
然后我们回到最初打开的ssh配置文件,在你的电脑SSH配置路径上,如果没打开的话,我们还是点击这里打开:
添加一行内容:
IdentityFile "C:\Users\NeoNexus\.ssh\id_rsa" 这里的路径要修改成你的配置路径,要记得这里的id_rsa文件并不带pub后缀因为这是私钥
添加后效果如下:
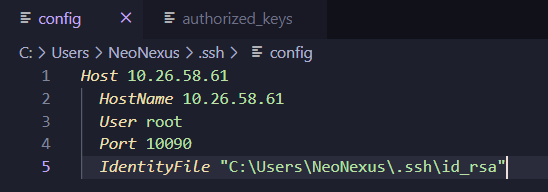
记得Ctrl+S保存修改
重启VSCode就可以愉快免密码直接使用了。